Is YOLOR Better and Faster than YOLOv4?
Jul 03, 2021
Introduction
YoloR just got released, but is it better and faster than YoloV4, Scaled YoloV4, YoloV5 and PP-YOLOv2? Well In order to answer this question we first have to review this ground breaking academic paper by Chein-Yao Wang and team to find out..
- What exactly is YoloR,
- Whats unique in its architecture,
- How it works,
- What results they achieved as well as
- How it compares to other state of the art models.
..So lets get right into it!
But before we get into the main content, we will be launching a Comprehensive Course on YoloR, in which we are going to be covering implementation, building various applications for object detection and DeepSORT tracking, as well as integrating it with a StreamLit UI for building your own YoloR web apps.
You can sign up for the YoloR Beginners Course right over HERE when it becomes available.
Back to the topic at hand. So we know what YOLO stands for right.. You Only Look Once right, but YoloR is slightly different. The authors labeled their paper You Only Learn One Representation — Unified Networks for Multiple Tasks — At first this does not make much sense, but after reading their paper or this article, you’ll see that the title wraps up what its about, quite nicely!

Explicit and Implicit Knowledge
So say that you and I had to look at a person for example, as humans, we can recognize that it’s a person quite easily. Well so can a Convolutional Neural Network (CNN). However, both you and I can also recognize where the hands and legs are, what the person is wearing, where they are located, is it in a room or outside, are they standing or jumping or playing Fortnight. A CNN can only do one thing and do that one task robustly, but fail miserably at other tasks. Why is this? Well it comes down to 2 things:
- Explicit, and
- Implicit Knowledge.
Explicit knowledge is known as normal learning, or things that you learn consciously. If I walk up to you and say that this is a doge, you will be like aha, that is doge.
Implicit knowledge on the other hand refers to the knowledge learnt subconsciously, sort of like riding a bike or learning how to walk. Its derived from experience. So both knowledge types learned through normal or subconscious learning will be encoded and stored in the brain to perform for various tasks.
Its also possible that if you apply the like transformation for the network to follow my channel Augmented Startups, that will help me to share my future implicit and explicit knowledge with you guys, see what I did there ;) haha…
Anyways…now you probably sitting there asking:
“Ritz this is all great but what does this all have to do with Object Detection and YoloR”!!
Great question! It’s the same question I asked myself when reading the paper. But stay with me for a moment and all will be unraveled.
The Unified Model

Now in terms of neural networks, knowledge obtained from observation is known as Explicit Deep Learning and corresponds to the shallow layers of a network. Implicit Deep Learning however corresponds to the deeper layers of a network, usually where the features are extracted. In simple terms, the explicit model will say it’s a drone, but the implicit model will have additional information, like identifying propellors, motors, battery, is it flying or grounded, broken or fixed. Just note that its not limited to only visual features, it can also include auditory and textual ques. I hope you are still with me, because this paper.. [sinister laugh😆].. is a tricky one.

Right, so having these two models, the authors combined both explicit and implicit knowledge in a unified network that can accomplish various tasks. Early on in the paper they do not mention what these task are, but if you browse through the experimentations section, they mention that they plan to do the following tasks like Object Detection, Instance Segmentation, Panoptic Segmentation, Keypoint detection, image captioning and more… But that is something for the future.
Lets dig in deeper into this unified model, the architecture and then we’ll delve into the results of this model.
Explicit Deep Learning
Explicit Deep Learning was just briefly touched on in the paper but they mentioned that this can be achieved using Detection Transform (DETr), Non-Local Networks and Kernel Selection. I know, I know… I was scared also when I’d seen these terms. But after digging into the references, in plain and simple English, these are just different architectures for object detection and classification. Remember earlier on we mentioned that Explicit Knowledge is based on observation, well the authors essentially used Scaled YOLOv4 CSP for their explicit model.
Implicit Deep Learning
Now on to Implicit Deep Learning. We will spend a bit more time here because this is the main focus of the paper. So this is where things get really technical, I swear I must have reread this section over 10 times to fully grasp what was actually being discussed. Nevertheless I’ll try my best to explain it in laymen’s terms. There’s a couple of ways in which we can implement Implicit Knowledge. These include
- Manifold Space Reduction,
- Kernel Alignment, and
- More Functions.
Manifold Space Reduction
For manifold space reduction, my understanding is that we reduce the dimensions of the manifold space so that we are able to achieve various tasks such as pose estimation and classification, amongst others. If you want to learn more about about dimensionality reduction, have a look at my lecture on Principle Component Analysis (PCA) and Support Vector Machine (SVM) HERE

Kernel Space Alignment
So they mention that in multi-task and multi-head neural networks, kernel space misalignment is a frequent problem. In order to deal with this problem, they perform both addition and multiplication of the output feature and implicit representations, so that the Kernel can be translated, rotated and scaled in such a way as to align each output kernel of a network. Haha, if this is all sounding like Greek to you, don’t worry let me help simplify it.
What they mean is that this is essentially important for aligning features of large and small objects in Feature Pyramid Networks (FPN). Feature pyramids are fundamentally basic components in recognition systems for detecting objects at different scales. You can imagine the amount of visual differences or disparity there are in pixels between objects that are far, to those that are close to your camera.

More Functions
In addition to the aforementioned techniques, they propose that you can also apply some operations for offset and anchor refinement as well as feature selection. Meaning that you can apply different operations to perform different tasks like either getting the class of the object, the bounding box or the mask amongst many other potential tasks .

Applying Implicit Knowledge into the Unified Network
This leads us up to applying Implicit knowledge into the Unified Network. Now just to recap, a unified network is a network that is a combination of both Implicit and Explicit knowledge. If we had to model a Conventional N etwork it would look something like this:

"Ritz you are literally speaking Greek again, please bestow some of your implicit and explicit knowledge upon me so that I may understand thee."
Haha okay okay…
Conventional Network Problem
So x is the observation, for example, you see a dog. Theta is the set of parameters of a neural network, f_θ represents the operation of the neural network, and ϵ is the error term. The authors state that when one trains a conventional neural network, the goal is to minimize the error to make f(x) with respect to θ as close to the target y as possible.
But now if we want to perform various other tasks like object segmentation and pose estimation for example, we would have to relax the error term to find the solution space for each task. This currently is quite challenging to do, but a solution that the authors proposed is to rather model the error term ϵ to find solutions for various tasks as you can see here.
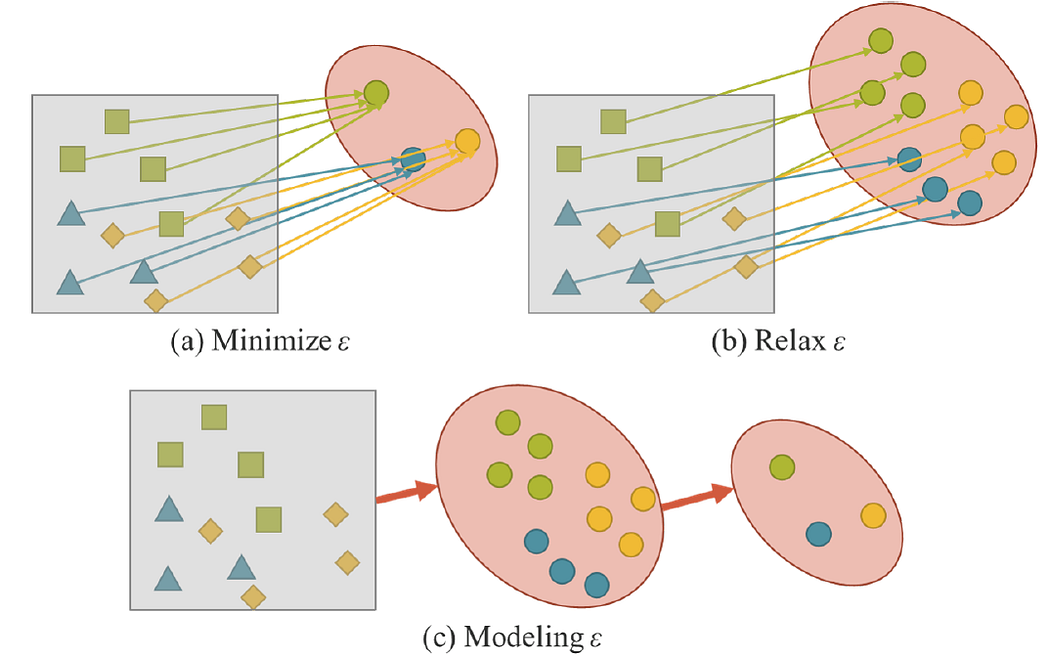
Unified networks

This is where unified networks come into the picture, we can now expand our equation to incorporate the implicit model with g theta and the explicit error from observation x together with the implicit error from z which they term the latent code. In layman's terms it just refers to the representation of compressed data that makes up the implicit knowledge. We can further simplify the equation to this.

Where the ⋆ represent some possible operators like addition or concatenation that combines f and g or, rather the explicit with the implicit models.
Modelling Implicit Knowledge
There’s a lot more more mathematics involved with the unified network architecture but lets now move on to how Implicit Knowledge can actually be modelled, which is in three ways:
- As a Vector,
- A Neural Network, or as a
- A Matrix.

Training
Training the model is just like any other model which is through the back-propagation algorithm.
Experiments
Cool we are getting closer to finally finding out if YoloR is really better than its other YOLO counterparts but first we have to discuss the experimental setup.
So in their experimental design the authors chose to apply implicit knowledge to three aspects including
- Feature alignments on Feature Pyramid Networks (FPN)
- Prediction Refinement, and
- Multi-task learning in a single model.
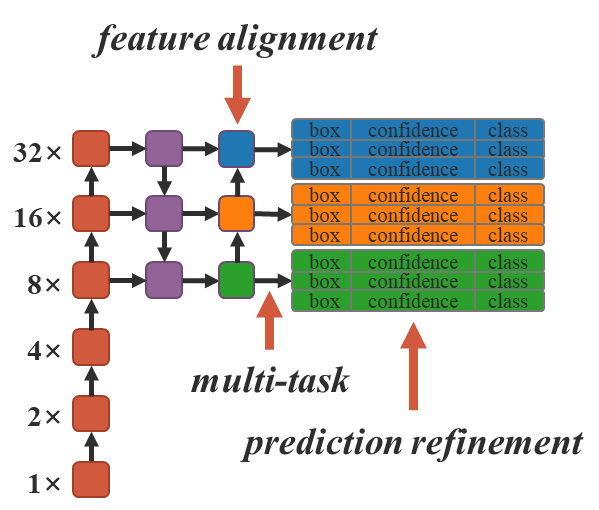
All of the of the concepts that we’ve mentioned earlier. The tasks that they covered were:
- Object Detection
- Multilevel image classifications, and
- Feature Embedding.
They use YOLOV4-CSP as their base line model and introduced implicit knowledge into the model and trained it on the MS-COCO Dataset. The way they tested the unified model was through Ablation Study, which is just a fancy-ass way to say that they are testing one method at a time to understand the contribution of the component to the overall system.

Implicit Knowledge for Object Detection
They followed the same training process as scaled-yolov4 in which they trained, from scratch, 300 epochs first and then fine tuned 150 epochs thereafter.

Results
And now for the moment you’ve all been waiting for which is the results. If you look at the baseline, you can see the effect of the implicit model compared to the baseline. When fine tuned you can see, that the results are even better.
Now looking at the comparison of the state of the art algorithms out there. You can see that in terms of accuracy YoloR is comparable but where it shines, is in its frame rate.

Its almost double the frame rate of Scaled YOLOv4 which is freaking amazing!!! If you look at the test run by the legend Alexey Bochkovskiy, they show an 88% in improvement in speed when compared to Scaled YOLOv4 and a 3.8% improvement in Average Precision compared to PP-Yolov2.

Concluding Remarks
In summary you can probably understand why the title of this paper is called You Only Learn One Representation (YOLOR)and then the second half of the title which is Unified Network for Multiple Tasks. Where the tasks can be anything like object detection, instance segmentation, keypoint detection, image captioning amongst many others.

Pat your self on the back, because now you have learnt how the integration of implicit knowledge along with explicit knowledge can prove very effective for multi-task learning under a single model architecture.
The authors say that they plan to extend the training to-multi-modal and multi-task models some time in the future. Great, so I really hope you learnt a lot and I really think that YoloR will be the next big thing in Computer Vision.
As I’ve mentioned before, if you enjoyed this introduction and want to learn how to build real world applications with YoloR that you can enroll in my Free YoloR Course over HERE.

Also if you would like me to share my future explicit and implicit knowledge with you, then you can follow me here on Medium. Otherwise if you are feeling generous, you can buy me a chai or coffee at this link over HERE
References
[1]You Only Learn One Representation: Unified Network for Multiple Tasks — Chien-Yao Wang et. al
From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



