Does Object Size Matter in Image Recognition? Unveiling the Impact of Size on Accuracy
May 26, 2023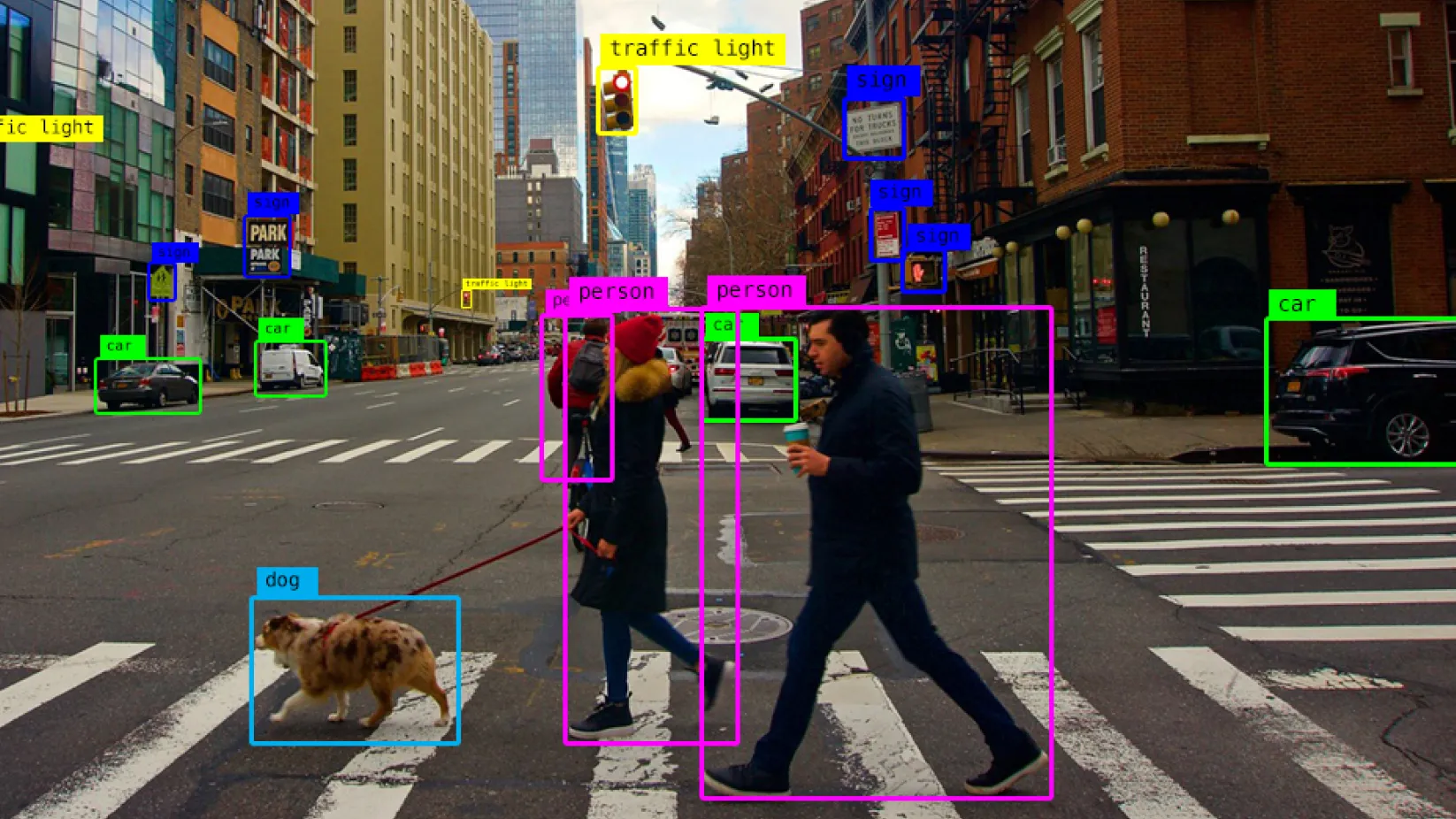
In the realm of computer vision and artificial intelligence, image recognition plays a pivotal role in a wide range of applications. From autonomous vehicles to medical diagnostics, accurate object recognition is essential for enabling machines to perceive and understand the visual world. One key question that arises in this domain is, "Does object size matter in image recognition?" In this article, we embark on a journey to explore the impact of object size on the accuracy of image recognition systems. Let's delve into the intricacies of scaling, feature extraction, and deep learning models to unravel the significance of size in image recognition algorithms.
Does Object Size Matter in Image Recognition?
Image recognition algorithms aim to identify objects within an image by analyzing their visual features. The size of an object can influence the accuracy of the recognition process. When an object occupies a small portion of an image, it may suffer from reduced visibility, leading to potential misclassification. Conversely, objects that are too large might lose fine details, making it challenging for algorithms to distinguish them from similar-looking objects. Therefore, object size does matter in image recognition, and optimizing the system to handle varying sizes is crucial for achieving higher accuracy.
The Impact of Scaling
Scaling refers to the process of resizing objects to ensure their compatibility with image recognition algorithms. It involves transforming the size of objects while preserving their proportions. When objects are scaled down, smaller details may be lost, affecting the recognition accuracy. On the other hand, scaling up objects can lead to image distortion, making it difficult for algorithms to extract meaningful features. Achieving an optimal balance during scaling is essential to maintain accuracy in object recognition tasks.
Feature Extraction and Size Considerations
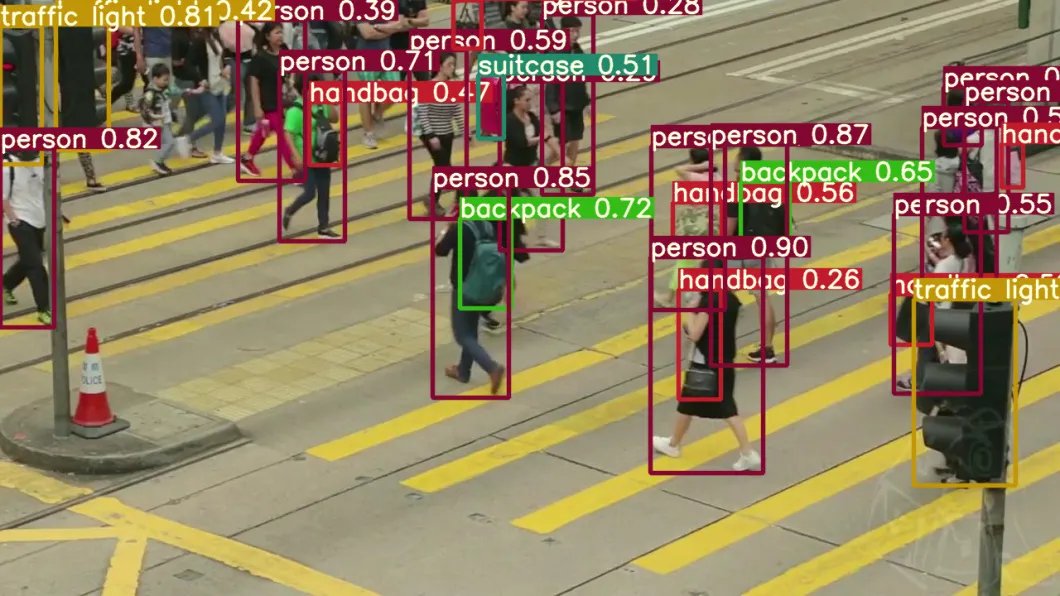
Feature extraction is a fundamental step in image recognition, where algorithms identify and analyze distinguishing characteristics of objects. The size of an object can significantly impact feature extraction. When objects are too small, their important features may become indistinguishable or imperceptible. Conversely, when objects are too large, certain features might dominate the image, overshadowing other crucial aspects. Achieving an appropriate size for objects aids in effective feature extraction and improves the accuracy of recognition models.

Deep Learning Models and Object Size
Deep learning models, such as convolutional neural networks (CNNs), have revolutionized image recognition. These models learn hierarchical representations of objects and can adapt to various sizes. However, the size of objects can still influence their performance. Large objects may require more computational resources and memory, leading to increased processing time. Moreover, if the training dataset primarily consists of small objects, the model might struggle to generalize well for larger objects. Adequate training and testing on diverse object sizes are necessary to ensure the robustness of deep learning models in image recognition tasks.
Strategies to Enhance Object Recognition Performance
To improve object recognition performance and address the impact of object size, several strategies can be employed:
1. Data Augmentation
Data augmentation involves generating additional training samples by applying various transformations to the existing dataset. This technique can help simulate objects of different sizes, angles, and orientations, enabling the model to learn robust features and generalize better to real-world scenarios.
2. Multi-Scale Approaches
Utilizing multi-scale approaches involves processing images at multiple resolutions or scales. This allows the model to capture details from both small and large objects. By incorporating different scales during training and inference, the system becomes more versatile in recognizing objects of varying sizes.
3. Region Proposal Techniques
Region proposal techniques aim to identify potential object regions within an image. These methods can assist in detecting objects of different sizes by proposing candidate regions for further analysis. By employing such techniques, the system can focus its attention on relevant areas and improve recognition accuracy.
4. Transfer Learning
Transfer learning involves leveraging pre-trained models on large-scale datasets and fine-tuning them for specific tasks. By using pre-trained models, which have already learned rich representations of objects, the system can benefit from their knowledge and adapt them to handle different object sizes effectively.
5. Ensemble Methods
Ensemble methods involve combining predictions from multiple models to make a final decision. By training and integrating multiple models that specialize in recognizing objects of different sizes, the system can achieve improved accuracy and robustness across a wide range of object sizes.
6. Continuous Evaluation and Iterative Improvement
Continuous evaluation and iterative improvement are crucial for enhancing object recognition performance. By regularly evaluating the system's performance on different object sizes, identifying weaknesses, and iteratively refining the models and strategies, accuracy can be continually improved.
Conclusion
In conclusion, the question "Does object size matter in image recognition?" holds significant importance in the field of computer vision. The size of an object can influence the accuracy of image recognition algorithms, affecting feature extraction, scaling, and deep learning models. By understanding the impact of object size and implementing appropriate strategies, such as data augmentation, multi-scale approaches, and region proposal techniques, the performance of image recognition systems can be enhanced. Continuous evaluation and iterative improvement further contribute to achieving optimal accuracy across diverse object sizes. As the field continues to advance, addressing the challenges associated with object size will play a vital role in developing more robust and reliable image recognition systems.
Ready to up your computer vision game? Are you ready to harness the power of YOLO-NAS in your projects? Don't miss out on our upcoming YOLOv8 course, where we'll show you how to easily switch the model to YOLO-NAS using our Modular AS-One library. The course will also incorporate training so that you can maximize the benefits of this groundbreaking model. Sign up HERE to get notified when the course is available: https://www.augmentedstartups.com/YOLO+SignUp. Don't miss this opportunity to stay ahead of the curve and elevate your object detection skills! We are planning on launching this within weeks, instead of months because of AS-One, so get ready to elevate your skills and stay ahead of the curve!

From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



