NeRF: Neural Radiance Fields
Jun 02, 2022NeRF: Neural Radiance Fields
Neural Radiance Field (NeRF)? Well, it sounds like a fancy term, isn’t it? However, this is a novel method in the rapidly evolving world of deep learning and computer vision.
NeRF is a fully connected neural network capable of generating novel views of various complex scenes. Isn’t that exciting? Perhaps, if you are still reading on, you would like to know how do the NeRF work? Let’s deep dive.
So, NeRF was initially proposed in the ECCV 2020 research paper titled “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis.” The NeRF method differs from the conventional ways of machine learning models performed with 3D data.
But why is the method considered a breakthrough in the field? Essentially, NeRF has gained prominence due to the ability to generate new views from various 3D scenes obtained from image data, including the possibility to define the 3D shape by optimizing continuous volumetric scenes.
Moving on… unlike the conventional machine learning models, NeRFs can learn directly from images without the need for convolutional layers. Another critical factor that makes this method very popular among researchers is the compressions with smaller weights than the training images used for the model.
How does it work?
Now this is the most critical part to wrap our heads around. Basically, working with 3D data has been a challenge for machine learning applications. Several techniques have been proposed, but the biggest drawback has been the requirement of a 3D model for the 3D representations. Therefore, producing 3D data has remained an expensive procedure. Besides, 3D reconstruction mechanisms for different types of objects have been implemented, but these methods have been reported to produce errors in reconstructions that can significantly impact the accuracy of the models.
NeRFs is based on a light field concept that signifies how light transports through the 3D volumes. Mainly, the input is in the form of a continuous 5D function, and the resultant output is obtained by describing the direction of light rays emitted in each direction of the coordinates in the space. So, a rendering loss function enables NeRFs to generate the views of a scene provided through input images representing a specific scene. Moreover, these input images are fed and rendered to produce a complete scene. As such, NeRFs are also very effective for generating synthetic image data.
If you are scratching your head wondering how is it possible, you should refer to figure below for some idea. However, for all the enthusiasts you can certainly be entertained by the entire buffet of all our computer vision courses here on Augmented Startups.
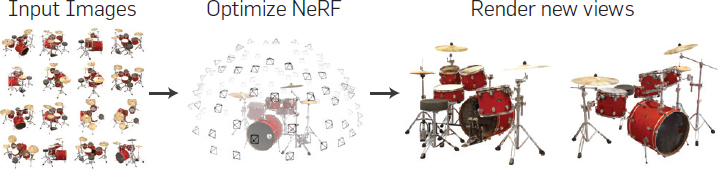
Figure.1: Workflow of a NeRF to generate new views (Adapted from Mildenhall et al., 2022). Source
However, we require some critical components for building such advanced models. For instance, these neural network models would require images taken from multiple scene angles, including camera positions, to capture these shots. Another important factor in adding people, objects, or moving elements in the input data requires the shots to be captured quicker as other motions while capturing these 2D images would mean blurriness when NeRFs generate an AI-based 3D scene.
Essentials for Implementing NeRF
We are aware now that the output produced by NeRFs are volumes with colors and densities that are entirely dependent on the direction of the view and the light radiance on a specific point. Therefore, each ray produces an output volume, and the combined volumes generate complex scenes. But implementing NeRF successfully requires a few essentials to be mindful of, such as:
1) To be aware of how to provide the camera rays through a scene for 3D point generation.
2) Inclusion of 3D points and 2D viewing directions to create the input for the neural network to reproduce RGB outputs and densities.
3) Implementing the appropriate technique to create 2D projections (i.e., volume rendering) from 3D point samples.
Given that neural rendering techniques differ in terms of the control they offer for scene appearance, the necessary inputs, outputs generated, and their network structures, it is crucial to understand the essential elements in a neural rendering approach to simplify the learning faster. For instance, we should be able to have address the necessities in terms of:
4) The components that we want to control and the conditions necessary for rendering the control signal.
5) The types of computer graphics modules infused in the neural rendering pipeline.
6) Evaluating the parameters to identify whether the concerned method provides explicit or implicit control for the expected output.
7) Understanding whether the method is targeted for multi-modal synthesizing.
NeRF: Recent Trends
Although various research has been proposed in the context of NeRFs, one of the industry leaders in deep learning, NVIDIA, has come up with the fastest NeRF to date.
Yeah, you guessed it right, NVIDIA that we are so familiar with logos on the laptops and known to accelerate our gaming experience and handle all the graphic related necessities
![]()
This NeRF model can learn high-resolution 3D scenes within seconds and render images out of the specific scene in milliseconds. I know a huge claim right? But it has certainly become a possibility. You can check out their product video here.
Furthermore, the company claims that the model can achieve more than 1000x speeds in some instances. Besides, the model takes seconds to train on dozens of still photos. Further, the vice president of graphics research at NVIDIA, David Luebke, suggests that NeRFs can densely capture the light radiating from objects or scenes, making them a critical revolutionary technology for 3D necessities.
I assume, it’s increasing your interest now?

Okay, okay, I am sharing more. An exciting piece of information gained from Instant NeRF developments by NVIDIA is that they can also be used to create avatars or scenes required for virtual reality. Similarly, video conference participants and the related environment can be captured in 3D with the help of this model, including scene reconstructions for 3D digital maps. However, a critical factor that makes Instant NeRF stand out among other NeRF models is that previous models could render appropriate scenes with good quality but took several hours to train, while Instant NeRF cuts down on the rendering time required.
Similarly, a recent NeRF approach has been proposed for 3D synthetic defocus. It is a thin lens imaging-based NeRF framework capable of directly rendering 3D defocus effects. Knowing that existing NeRF methods generate 3D defocus more in a post-processing approach, this framework enables an inverse thin lens imaging approach to provide the beam path for every point on the sensor plane, while frustum-based volume is implemented for rendering purposes of each pixel in the beam path. Besides, the design is efficient for the NeRF model as it includes a probabilistic training approach to simplify the training process.

Figure.2: Results of NeRFocus model for 3D Synthetic Defocus (Adapted from Yinhuai Wang et al.). Source
Most recently, a learning framework called pixelNeRF has been proposed to predict a continuous neural scene representation from one or fewer image inputs. This approach enables the network to be trained for multiple scenes but with a unique ability to learn a scene prior, which allows it to produce novel views in a feed-forward manner. Therefore, this specific volume rendering approach for NeRF enables the model to be trained directly from images without 3D supervision.
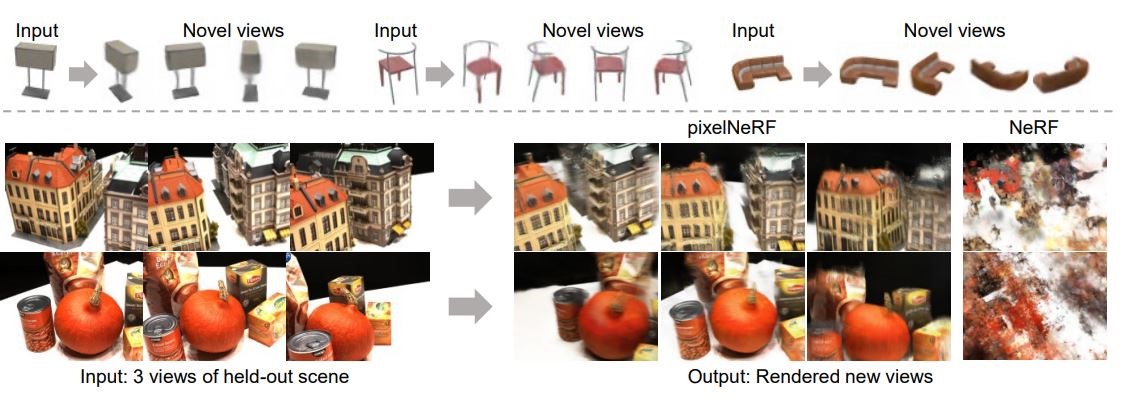
Figure.3: pixelNeRF Rendered Views (Adapted from Alex Yu et al.). Source
The competition is getting heated in the industry with an explosion of NeRF research, with several aiming to improve the slow training and rendering time constraints identified from the original NeRF research.

Some of these research works are:
NeRFplus focuses on addressing the parametrization problem occurring during the 360-degree capture of objects within unbounded 3D scenes and large-scale objects using NeRF. This method improves the view synthesis significantly.
AutoInt is a new framework that integrates signals with implicit neural representations and applications to volume rendering. The proposed framework focuses on improving the extreme computation and memory requirements due to volume integration necessities during training and inference.
KiloNeRF is proposed to address the challenges associated with slow rendering in NeRFs. This approach includes the separation of the workload mainly related to the querying of the network by providing a smaller multilayer perceptron (MLP). Therefore, the querying of each MLP causes each scene representation to be processed, leading to performance improvement and requiring lower storage.
Besides, there are new studies that aim at capturing dynamic scenes by using different schemes. Similarly, upcoming studies also emphasize creating NeRFs for portraits of people and relighting enhancements to relight a particular scene. On the other hand, generative models for radiance fields are developed for rendering shapes effectively.
Conclusion
Radiance fields have transformed the approach of computer vision models in dealing with 3D data. Besides, the NeRF models are rapidly bridging the gap between how 3D scenes can be produced quickly and effectively with high quality. Moreover, novel research works are continuously proposed to improve each of the challenges of the previous offerings. Additionally, some works aim to enhance real-world applications in terms of accurate reconstructions from unstructured images, while some have opted for reconstructing diagnostic images for better image rendering and diagnosis. Therefore, NeRFs are gradually gaining a foothold in various applications, and in the upcoming years, we will be able to witness remarkable landmarks using NeRFs.
So, are you still wondering how you can master these skills to build such excellent innovative solutions? Check out our computer vision courses to help develop your career path. We offer a 6-in-1 mega course to becoming a computer vision expert. Still, wondering? Come enroll in our courses and stand out in the industry as a top AI developer with exceptional skillsets.

From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



