Worlds Smallest AI Super Computer – Jetson Xavier NX
Apr 16, 2020
NVIDIA launched its new member for the Jetson class of smaller processing units – the Jetson Xavier NX. The size of the entire setup is smaller than a normal sized debit or credit card. The module although not the smallest in business but more than makes up for its size with the processing capabilities and other qualities that it has to offer.
The earlier launches like Jetson Nano, the smallest GPU based device, will also have its compatibility with the latest Xavier NX with the pin compatibility making it possible to port the AIoT applications deployed on the Nano. The new device has been launched to ensure compatibility with all major AI frameworks, including the likes of PyTorch [1], TensorFlow [2] etc.

Attributes of Xavier NX
NVIDIA’s website [3] claims that the new device is capable of delivering upto 14 terra operations per seconds [4] also known as TOPS with the power consumption of 10W, with the power consumption of 15W it is capable of doing 21 TOPS, making it possible to run multiple neural networks in parallel or to process data from multiple sensors of variable resolutions.
In line with the existing family members of the jetson family Xavier NX also runs CUDA-X AI [5] software making it easier to have an optimized inference for deep learning architectures. The CPU for Xavier NX has 6-Core Carmel ARM 64-bit, 4MB L3 and 6MB of L1 cache, making it possible to support the 6 CSI cameras over 12 MIPI [6] CSI-2 lanes. The RAM for the new device is pegged at 8GB 128 bit, that can perform data transfers at the rates of 51 GB/ sec. The default operating system for the device is Ubuntu based Linux operating system.
Performance on Popular Architectures
The performance graphs of the different devices in the similar line from Qualcomm Intel class can be seen in the figure below and we can easily see that the new NVIDIA Xavier is easily one of the best in the business as of today.
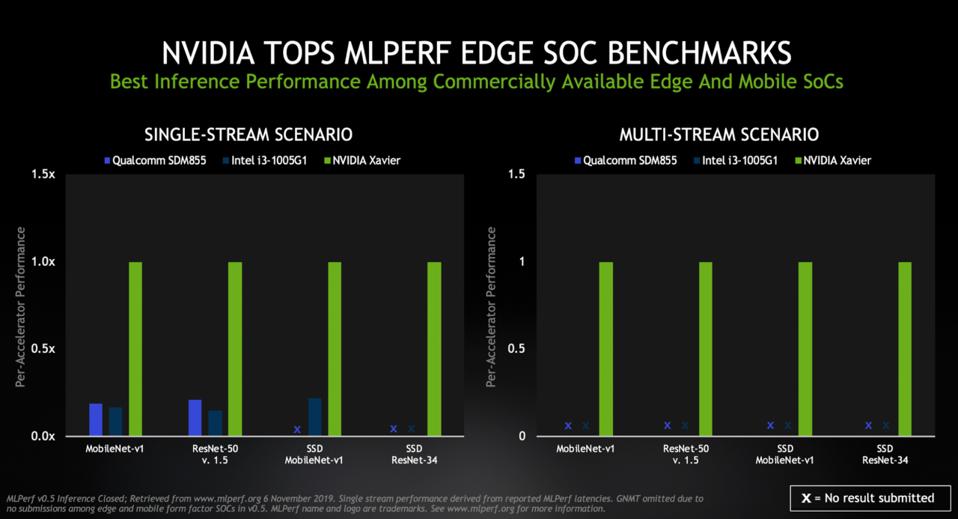
The new architecture has improved energy efficiency that allows it to use the fraction of the energy of the exiting hardware and still deliver speed enhancements in the ranges of 20x.
How it Compares with Similar Products
The new hardware is capable of using the NVIDIA SDK tools for enhanced performance on the inference side, as the tool enable the conversion of trained models into the TensorRT, which makes it possible to increase the inference speed of the existing architectures manifolds.
- Jetson Nano and Xavier NX, of the all available hardware in the market are the most affordable devices, with the high end computing performance.
- The size of the devices enables the use of the devices in self driving drones, miniature autonomous robots etc.
- The computing power with optimized energy consumption will enable the use of the device for sustained period of time making the automation more sustainable and less energy consuming.
There are a significant number of improvements other than the ones stated above, some of the significant difference that makes the new hardware exceedingly different from the existing architecture.
- The new packs a bigger punch in computational power despite having the similar size to that of the Nano 69.6 mm x 45 mm
- It can support a higher number of camera lanes via virtual channels
- Data Processing speed is almost double to that of Nano and is very comparable to its bigger counterpart Jetson's TX2, at 51.2 GB for Xavier and 59.7 GB for TX2, despite it consuming only a fraction of the energy.

Conclusion
NVIDIA has moved quickly to capture the fast growing AI market, with its domination in the training architectures, with the products like NVIDIA Tesla K-80, P100, T4 GPUs already dominating the market. It now is doing its best to capture the inference segment as well with the Jetson products line, which are smaller, more energy efficient compared to their bigger peers.
References
- https://pytorch.org/
- https://www.tensorflow.org/
- https://www.nvidia.com/
- https://en.wikipedia.org/wiki/FLOPS
- https://www.nvidia.com/en-us/technologies/cuda-x/
- https://www.mipi.org/specifications/csi-2
From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



