Top 5 Object Tracking Methods
Mar 05, 2022
Object tracking aims at estimating bounding boxes and the identities of objects in videos. It takes in a set of initial object detection, develops a visual model for the objects, and tracks the objects as they move around in a video. Furthermore, object tracking enables us to assign a unique ID to each tracked object, making it possible for us to count unique objects in a video. Often, there’s an indication around the object being tracked, for example, a surrounding square that follows the object, showing the user where the object is.

Object Detection and Tracking using YOLOR and DeepSORT
Object tracking has a wide range of applications in computer vision, such as surveillance, human-computer interaction, traffic flow monitoring, human activity recognition.
Simple Online And Realtime Tracking (SORT)
Simple Online And Realtime Tracking (SORT) is a lean implementation of a tracking-by detection framework. Keeping in line with Occam’s Razor, it ignores appearance features beyond the detection component. SORT uses the position and size of the bounding boxes for both motion estimation and data association through frames. Faster RCNN is used as the object detector. The displacement of objects in the consecutive frames is estimated by a linear constant velocity model which is independent of other objects and camera motion. The state of each target is defined as x = [u, v, s, r, u,’ v,’ s’] where (u,v) represents the center of the bounding box r and u indicate scale and aspect ratio. The other variables are the respective velocities.
For the ID assignment, i.e., data association task the new target states are used to predict the bounding boxes that are later on compared with the detected boxes in the current timeframe. The IOU metric and the Hungarian algorithm are utilized for choosing the optimum box to pass on the identity. SORT achieves 74.6 MOTA and 76.9 IDF1 on the MOT17 dataset with 291 ID switches and 30 FPS.
DeepSORT
Despite achieving overall good performance in terms of tracking precision and accuracy, SORT has a high number of identity switches. It fails in many of the challenging scenarios like occlusions, different camera angles, etc. To overcome these limitations DeepSORT replaces the association metric with a more informed metric that combines motion and appearance information. In particular, a “deep appearance” distance metric is added. The core idea is to obtain a vector that can be used to represent a given image. To do this DeepSORT creates a classifier and strips the final classification layer, this leaves us with a dense layer that produces a single feature vector.

In addition to that, DeepSORT adds extra dimensions to its motion tracking model. The state of each target is denoted on the eight-dimensional state space (u, v, γ, h, x,˙ y,˙ γ, ˙ h˙) that contains the bounding box center position (u, v), aspect ratio γ, height h, and their respective velocities in image coordinates. These additions enable DeepSORT to effectively handle challenging scenarios and reduce the number of identity switches by 45%. DeepSORT achieves 75.4 MOTA and 77.2 IDF1 on the MOT17 dataset with 239 ID switches but a lower FPS of 13.
FairMOT
Approaching object tracking from a multi-task learning perspective of object detection and re-ID in a single network is appealing since it allows shared optimization of the two tasks. However, the two tasks tend to compete with each other. In particular, previous works usually treat re-ID(re-Identification) as a secondary task whose accuracy is heavily affected by the primary detection task. As a result, the network is biased to the primary detection task which is not fair to the re-ID task.

Comparison of the existing one-shot trackers and FairMOT. The three methods extract re-ID features differently. TrackR-CNN extracts re-ID features for all positive anchors using ROI-Align. JDE extracts re-ID features at the centers of all positive anchors. FairMOT extracts re-ID features at the object center
FairMOT is a new tracking approach built on top of the anchor-free object detection architecture CenterNet. The detection and re-ID tasks are treated equally in FairMOT which essentially differs from the previous “detection first, re-ID secondary” frameworks. It has a simple network structure that consists of two homogeneous branches for detecting objects and extracting re-ID features.
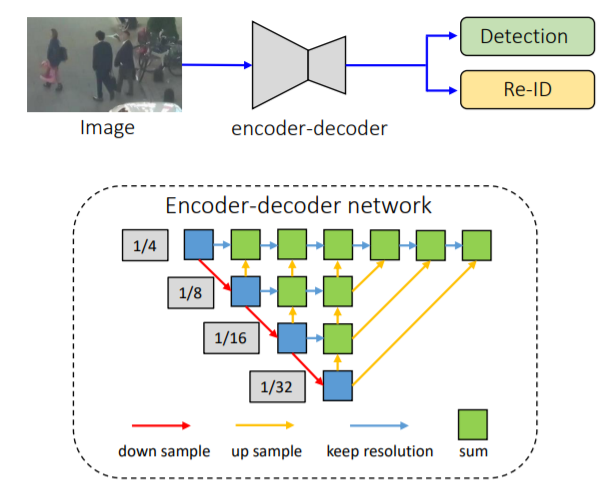
Overview of FairMOT and its encoder-decoder network
FairMOT adopts ResNet-34 as the backbone as it offers a good balance between accuracy and speed. An enhanced version of Deep Layer Aggregation (DLA) is applied to the backbone to fuse multi-layer. In addition, convolution layers in all up-sampling modules are replaced by deformable convolutions so that they can dynamically adjust the receptive field according to object scales and poses. These modifications also help to solve the alignment issue.
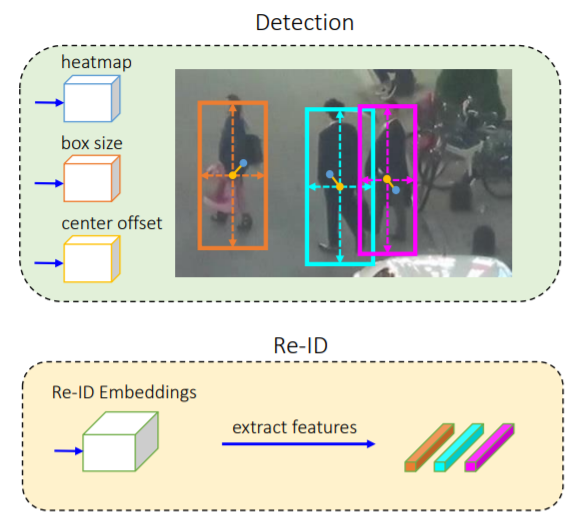
Detection and Re-ID branches
The detection branch is built on top of CenterNet, three parallel heads are appended to DLA-34 to estimate heatmaps, object center offsets, and bounding box sizes, respectively. The Re-ID branch aims to generate features that can distinguish objects. Ideally, affinity among different objects should be smaller than that between the same objects. To achieve this goal, FairMOT applies a convolution layer with 128 kernels on top of backbone features to extract re-ID features for each location. The re-ID features are learned through a classification task. All object instances of the same identity in the training set are treated as the same class. All these optimizations help FairMOT achieve 77.2 MOTA and 79.8 IDF1 on the MOT17 dataset with 25.9 FPS running speed.
TransMOT
Advances in deep learning have inspired us to learn spatial-temporal relationships using deep learning. Especially, the success of Transformer suggests a new paradigm of modeling temporal dependencies through the powerful self-attention mechanism. But transformer-based trackers have not been able to achieve state-of-the-art performance for several reasons:
- Videos can contain a large number of objects. Modeling the spatial-temporal relationships of these objects with a general Transformer is inefficient because it does not take the spatial-temporal structure of the objects into consideration.
- It requires a lot of computation resources and data for a transformer to model long-term temporal dependencies.
- The DETR-based object detector used in these works is still not state-of-the-art
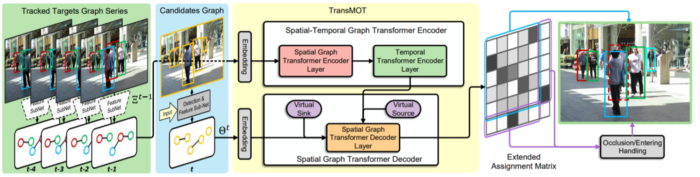
Overview of TransMOT
TransMOT is a new spatial-temporal graph Transformer that solves all these issues. It arranges the trajectories of all the tracked objects as a series of sparse weighted graphs that are constructed using the spatial relationships of the targets. TransMOT then uses these graphs to create a spatial graph transformer encoder layer, a temporal transformer encoder layer, and a spatial transformer decoder layer to model the spatial-temporal relationships of the objects. The sparsity of the weighted graph representations makes it more computationally efficient during training and inference. It is also a more effective model than a regular transformer because it exploits the structure of the objects.
To further improve the tracking speed and accuracy, TransMOT introduces a cascade association framework to handle low-score detections and long-term occlusions. TransMOT can also be combined with different object detectors or visual feature extraction sub-networks to form a unified end-to-end solution. This enables developers to leverage state-of-the-art object detectors for object tracking. TransMOT achieves 76.7 MOTA and 75.1 IDF1 on the MOT17 dataset with 9.6 FPS.
ByteTrack
Most tracking methods obtain identities by associating detection boxes with scores higher than a threshold. The objects with low detection scores are simply ignored, which brings non-negligible true object missing and fragmented trajectories. BYTE is an effective association method that utilizes all detection boxes from high scores to low ones in the matching process.
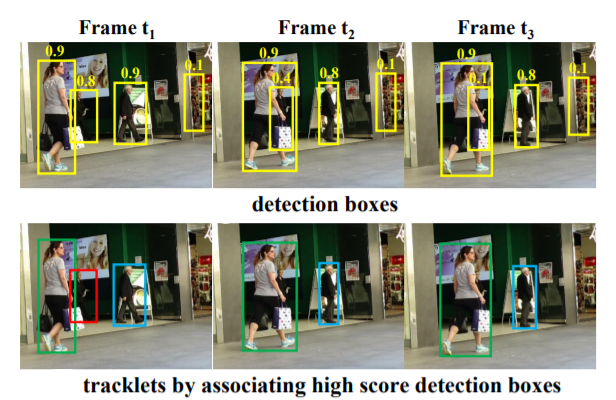
In frame t1, three different tracklets are initialized as their scores are all higher than 0.5. However, in frame t2 and frame t3 when occlusion happens, the red tracklet’s corresponding detection score becomes lower i.e. 0.8 to 0.4 and then 0.4 to 0.1. These detection boxes are eliminated by the thresholding mechanism and the red tracklet disappears. On the other hand, if we take every detection box into consideration, more false positives will be introduced, for example, the right-most box in frame t3.

BYTE is built on the premise that the similarity with tracklets provides a strong cue to distinguish the objects and background in low score detection boxes. BYTE first matches the high score detection boxes to the tracklets based on motion similarity. It uses Kalman Filter to predict the location of the tracklets in the new frame. The motion similarity is computed by the IoU of the predicted box and the detection box. Then, it performs the second matching between the unmatched tracklets, i.e. the tracklet in the red box, and the low score detection boxes. As a result, the occluded person with low detection scores is matched correctly to the previous tracklet and the background is removed.
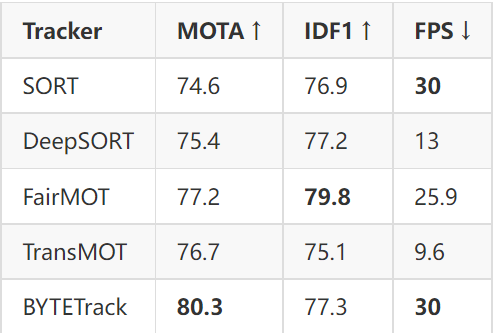
Performance metrics for the trackers on the MOT17 benchmark
When applied to 9 different state-of-the-art trackers, BYTE achieves consistent improvement on IDF1 scores. To put forwards the state-of-the-art performance, BYTE was equipped with the high-performance detector YOLOX, to create a strong tracker named ByteTrack. ByteTrack is the first tracking approach to achieve 80.3 MOTA, 77.3 IDF1, and 63.1 HOTA on MOT17 with 159 ID switches 30 FPS running speed on a single GPU.

Want to learn more about object tracking and implement your own computer vision applications? Enroll in our YOLOR course HERE today! It is a comprehensive course that covers not just the state-of-the-art computer vision models such as YOLOR and DeepSORT but also uses them to solve a wide range of real-world problems.

From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



