Top YOLO Variants Of 2021
Mar 25, 2022
Object detection aims to mark the region of the image that contains objects with bounding boxes and classify them. This ability to recognize the Region-Of-Interest (ROI) makes it fundamental to many downstream tasks, such as object tracking, image segmentation, landmark detection, and more. The YOLO family of models is among the most prominent object detectors due to their ability to provide state-of-the-art performance in real-time. 2021 has been an eventful year for YOLO, we have seen the introduction of five new models.

YOLOF
Feature pyramids are a common construct in state-of-the-art object detection models. The general perception is that the success of FPNs is due to the fusion of multiple-level features, not the divide-and-conquer function. The authors of You Only Look One-level Feature, YOLOF, studied the influence of FPN’s two benefits individually. They came to the conclusion that the multi-scale feature fusion benefit of FPNs is far away less critical than the divide-and-conquer benefit.

The sketch of YOLOF, which consists of three main components: the backbone, the encoder, and the decoder.
Based on the findings they created YOLOF, a straightforward and efficient framework with single-level features. It achieved results on par with its multi-feature counterparts with a 2.5 × speed up against RetinaNet+ and 7 x speed up against DETR.
You can read more about YOLOF here.
YOLOR

Looking at the same data features from different angles allows humans to answer a plethora of questions, something that’s not currently feasible for CNNs
Humans learn on two levels, through purposeful learning (explicit knowledge), and subconsciously (implicit knowledge). It is the combination of these two that enables humans to process data so efficiently, even unseen data. In addition to that, humans can analyze the same data points from different perspectives for different objectives. On the other hand, convolutional neural networks only look at data from a single perspective, and the features outputted by CNNs are limited to one task. This is because CNNs only make use of the features from output neurons, the explicit knowledge; while ignoring the abundant implicit knowledge.
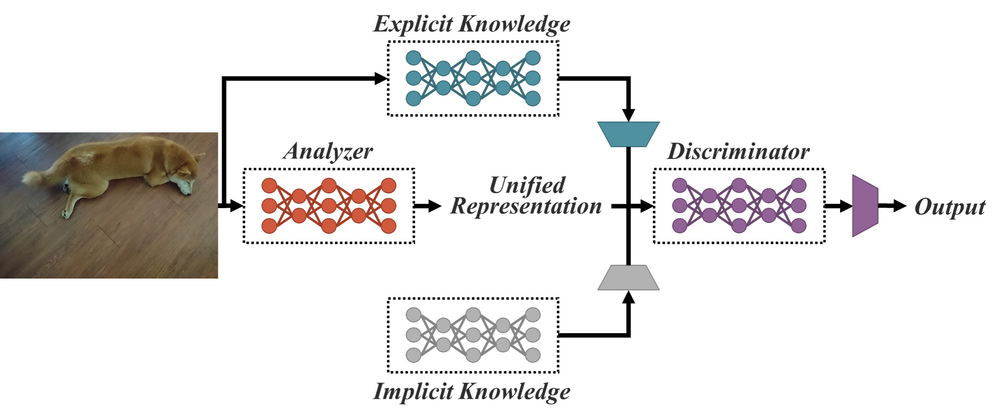
YOLOR’s unified network: combining explicit knowledge and implicit knowledge for serving multiple tasks
YOLOR (You Only Learn One Representation) is a unified network that integrates implicit knowledge and explicit knowledge. It pre-trains an implicit knowledge network with all of the tasks present in the COCO dataset to learn a general representation, i.e., implicit knowledge. YOLOR then trains another set of parameters that represent explicit knowledge for a specific task. Both implicit and explicit knowledge are used for inference.
You can read more about YOLOR here.
YOLOS
Vision Transformer (ViT) showed us that the standard Transformer encoder architecture inherited from NLP can perform surprisingly well on image recognition at scale. Transformers are made to transfer, so a question arises: can vision transformers transfer to more complex computer vision tasks such as object detection?
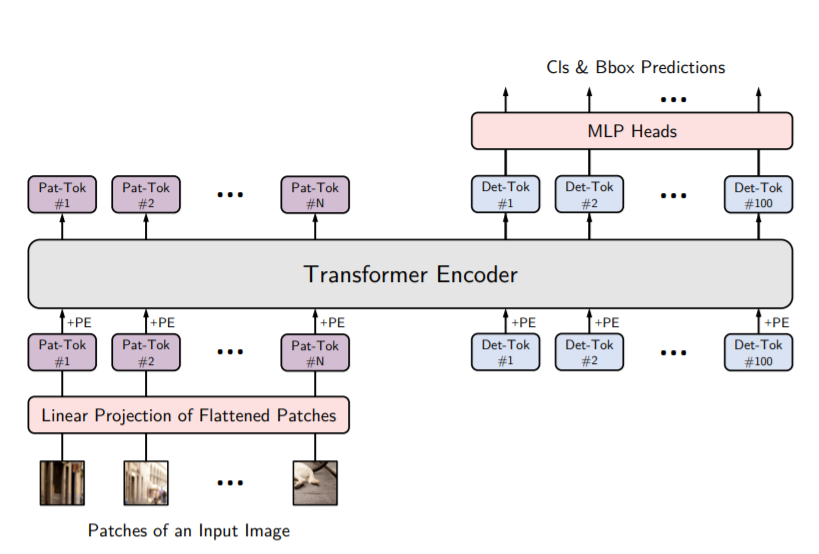
You Only Look at One Sequence (YOLOS) is a series of object detection models based on the ViT architecture with the fewest possible modifications and inductive biases. YOLOS closely follows the ViT architecture, there are two simple changes:
- YOLOS drops the [CLS] token used for image classification and adds one hundred randomly initialized detection [DET] tokens to the input patch embedding sequence for object detection.
- The image classification loss used in ViT is replaced with a bipartite matching loss to perform object detection similar to DETR.
YOLOS was compared with some modern CNN-based object detectors like DETR and YOLOv4. The smaller YOLOS variant YOLOS-Ti achieved impressive performance compared to the highly-optimized object detectors. On the other hand, the larger YOLOS models we less competitive.
At this stage, YOLOS is basically a proof-of-concept with no performance optimizations. Its impressive performance demostrates that pure vision transformers can transfer pre-trained general visual representations from image-level recognition to the more complicated 2D object detection task.
You can read more about YOLOS here.
YOLOX

Square grid and anchor boxes
YOLO models take the image and draw a grid of different small squares. And then from these small squares, they regress off of the square to predict the offset they should predict the bounding box at. These grid cells alone give us tens of thousands of possible boxes, but YOLO models have anchor boxes on top of the grid. Anchor boxes have varying proportions that allow the model to detect objects of different sizes in different orientations.
The combination of these two enables the model to detect a wide range of objects, but they also pose an issue in the form of high computation costs. Another limiting aspect of YOLO models is the coupling of bounding box regression and object detection tasks that causes a bit of a tradeoff.
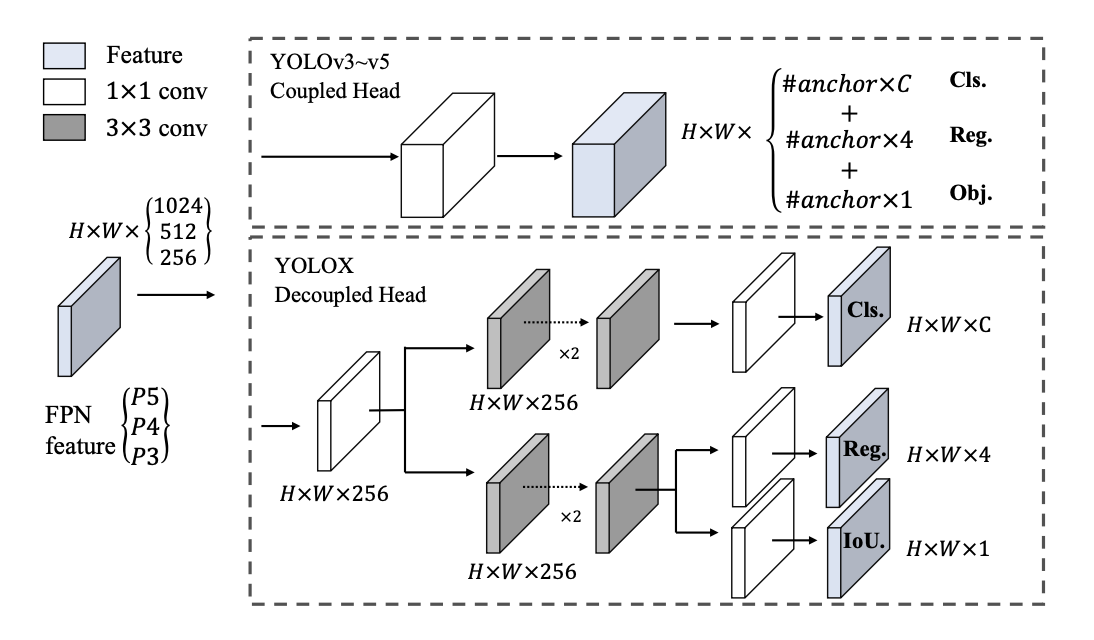
Difference between YOLOv3 head and the decoupled head used by YOLOX
YOLOX addresses both of these limitations, it drops the construct of box anchors altogether. This results in improved computation cost and inference speed. YOLOX also decouples the YOLO detection head into separate feature channels for box coordinate regression and object classification. This leads to improved convergence speed and model accuracy.
You can read more about YOLOX here.
YOLOP
Computer vision models are an essential part of autonomous driving systems. To help the driving system operate the vehicle, the perception system needs to perform tasks such as segmenting the drivable area, detecting lanes and traffic objects. Now there are a plethora of state-of-the-art algorithms that tackle each of these problems individually. However, these have high computation costs and can not perform real-time inference on embedded systems usually available in autonomous cars. YOLOP, You Only Look Once for Panoptic Driving Perception, takes a multi-task approach to these tasks and leverages the related information to build a faster, more accurate solution.

YOLOP has one shared encoder and three decoder heads to solve specific tasks. There are no complex shared blocks between different decoders to keep the computation to a minimum and allow for easier end-to-end training. It was tested on the BDD100K dataset against the state-of-the-art models for the three tasks. YOLOP outperformed or matched the state-of-the-art models. It is the first model to perform the three panoptic perception tasks simultaneously in real-time on an embedded device like Jetson TX2 and achieve state-of-the-art performance.
You can read more about YOLOP here.
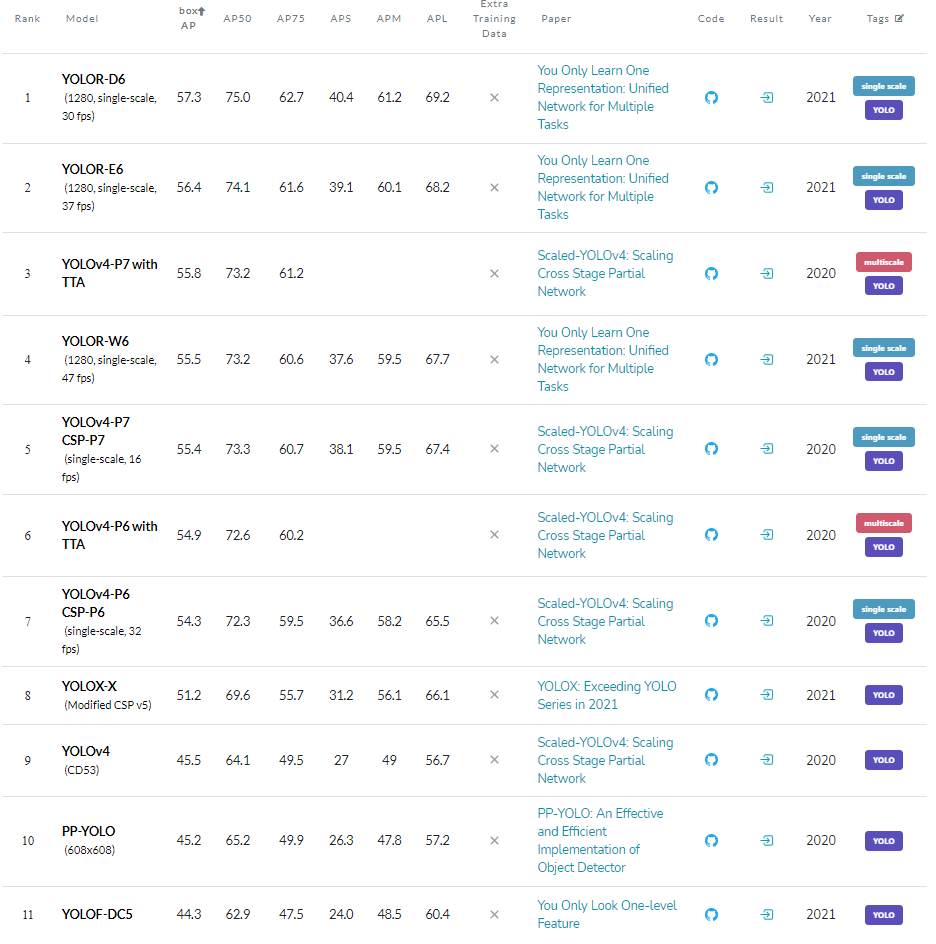
Leaderboard of all YOLO models for object detection on COCO test-dev dataset
Out of these five, only YOLOR and YOLOX make it to the top 10 of the COCO benchmark. YOLOF misses the tenth spot by <1 box AP. YOLOP is more focused on being a more well-rounded panoptic perception system and YOLOS is a proof-of-concept so expecting them to outperform highly optimized models would be unfair.
Which YOLO variant has made the biggest leap in your opinion, let us know down in the comments.

Do you want to learn one of the most pivotal computer vision tasks — object detection — and convert it into a marketable skill by making awesome computer vision applications like the one shown above? Enroll in our YOLOR course HEREtoday! It is a comprehensive course that covers not only object detection fundamentals and the state-of-the-art YOLOR model, but also the implementation of various use-cases & applications like the one shown above.

From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



