YOLACT - Real Time Instance Segmentation
Apr 13, 2020
Instance Segmentation[1] is one of the hottest areas for research in the field of Artificial Intelligence. The process in its present form relatively computationally expensive, therefore the present architectures that are able to generate the best results are not very suitable for “real-time” applications.
The networks that yield good results in instance segmentation are FCIS[2], Mask-R CNN [3], RetinaMask[4], PA-Net[5] etc. These frameworks although perform relatively well but the inference obtained from them can’t be used in “real-time” due to the computational complexity that is involved in the creation of such systems, the sheer number of parameters makes it impossible for these network to perform on machines with lower computational capability. The task therefore requires a different architecture that is able to perform in the “real time” computations.
YOLACT to the rescue
YOLACT [6] (You only look at the coefficients) is a more optimized version for instance segmentation, which has secured a good reputation for its speed and accuracy trade-offs. It is able to achieve 29.8 mean Average Precision (mAP) on MS COCO at 33 frames per second, much faster than the other competitive frameworks.

Type caption (optional)
So what is YOLACT
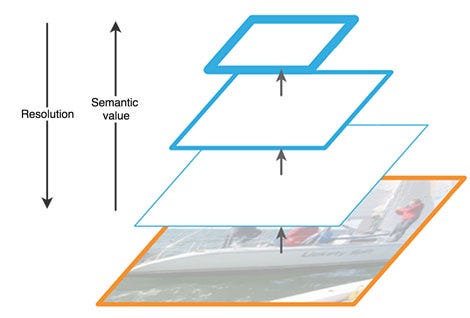
YOLACT uses ResNet-101 [7] with FPN (Feature Pyramid Networks) [8] that helps in creating pyramids of feature maps of high resolution images rather than the Conventional Pyramid of Images approach, therefore reducing the time and requirements of computational capabilities. The computational cost is cut further with the use of only higher level extracted feature layers that have higher semantic value (The resolution and semantic value are both inversely proportional in the given architecture as demonstrated in the figure below).
The architecture has a top-down pathway that allows for the construction of the higher resolutional layers from these semantic rich layers, in order to keep the detection abilities for the locations of the objects after upsampling and downsampling there are lateral connections between the reconstructed layers and the corresponding feature maps.

Source: [9]
The up-sampled layers then interact with Prototypical Neural networks [10] and a Prediction head that has the mask coefficients for the respective detections, all the frames obtained from the prediction head are then put through a Non-maximum suppression where we only receive the detections that have the highest coefficients of detection. The combined output is then cropped and the colors for different instances are then generated from thresholding the final output.
How it compares with the existing architectures:
Speed
YOLACT has a number of advantages over the existing architectures, one of the most significant ones will be the speed of predictions. As mentioned earlier YOLACT is the only existing architecture that can actually deliver “real-time” inference. The following figure compares the performance of different architectures multiple variations of the YOLACT:

Type caption (optional)
As is clear from the comparison chart above YOLACT is quicker with its inference than all the other nearest competitors in all its variants. The accuracy and speed are a trade-off and some variations of YOLACT are able to beat FCIS in terms of the accuracy as well.
Higher Quality of Masks
The masks generated from YOLACT are of higher quality than the existing architectures, as the masks actually use the entire image space domain and that therefore doesn’t cause any loss from the repooling.

Source : [11]
Summary
In conclusion the YOLACT architecture has a little disadvantage over the existing architecture in terms of accuracy, but it more than make up for that with its speed in inference.
There are plenty of real world applications where this kind of behavior is desirable for example with: object detection on mobile devices (apps that use filters for images etc), autonomous vehicles, Geo-sensing, precision agriculture (for its ability to generate better masks), face segmentation, e-commerce etc.
These areas have considerable scope for the real-time implementation of YOLACT where it outperforms the existing architectures in terms of its ability to generate better masks and speed. YOLACT is a relatively young architecture and the results at this early stage are promising, with time as more and more people are able to work on it, the performance will show significant improvements.
To Learn More AI, Click Here
References:
From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.




{kind=link}
{kind=link}