You Only Look At One Sequence(YOLOS): What Can’t Transformers Do?
Mar 26, 2022
Transformers have established their importance in natural language processing (NLP), their ability to learn a general language representation and transfer it to specific tasks has made them invaluable. And with the advent of Vision Transformer (ViT) we saw that standard Transformer encoder architecture inherited from NLP can perform surprisingly well on image recognition at scale. Pre-trained transformers can be fine-tuned on sentence-level tasks, as well as more complex tasks that involve producing fine-grained output at the token level. This raises a question: Can vision transformers like ViT transfer to more complex computer vision tasks such as object detection?
ViT-RCNN already leveraged a pre-trained ViT as the backbone for an R-CNNobject detector. But it still relies heavily on convolution neural networks and strong 2D inductive biases. Simply put, ViTFRCNN interprets the output sequence of ViT to 2D spatial feature maps and utilizes region-wise pooling operations & R-CNN architecture to decode the features for object-level perception. There have been other similar works, like DEtection TRansformer (DETR), that introduce 2D inductive bias by leveraging pyramidal feature hierarchies and CNNs.

However, these architectures are performance-oriented and they don’t reflect the properties of the vanilla Transformers. ViT is designed to model long-range dependencies and global contextual information instead of local and region-level relations. Moreover, ViT doesn’t have hierarchical architecture like CNNs to handle the large variations in the scale of visual entities. But Transformers are born to transfer, so we can’t dismiss them without testing whether a pure ViT can transfer pre-trained general visual representations from image-level recognition to the much more complicated 2D object detection task
To test the efficacy of vanilla transformer models, Yuxin Fang, Xinggang Wang, et al, created You Only Look at One Sequence (YOLOS), a series of object detection models based on the ViT architecture with the fewest possible modifications and inductive biases.
Architecture & Approach
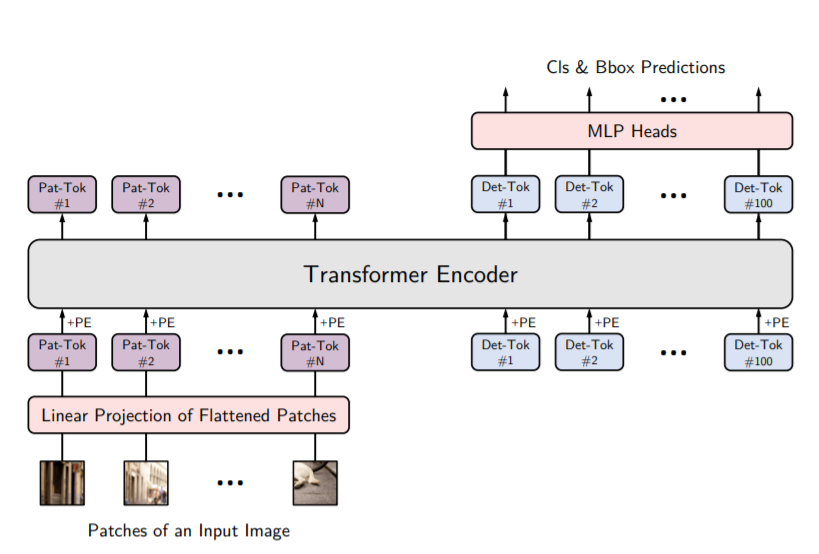
YOLOS closely follows the ViT architecture, there are two simple changes:
- YOLOS drops the [CLS] token used for image classification and adds one hundred randomly initialized detection [DET] tokens to the input patch embedding sequence for object detection.
- The image classification loss used in ViT is replaced with a bipartite matching loss to perform object detection similar to DETR.
YOLOS is pre-trained on the smaller ImageNet-1k dataset. It is then fine-tuned using the COCO object detection dataset. It is important to reiterate that the whole model isn’t trained on the COCO dataset per se, YOLOS learns a general representation using ImageNet-1k and is then fine-tuned on the COCO dataset. If you’ve trained a custom object detection model, or simply employed transfer learning, you have taken a pre-trained model, frozen most of its layers, and fine-tuned the final few layers for your specific dataset/use case. Similarly, in YOLOS all the parameters are initialized with the ImageNet-1k pre-trained weights except for the MLP heads for classification & bounding box regression, and the one hundred [DET] tokens.
The randomly initialized detection [DET] tokens are used as substitutes for object representation. This is done to avoid inductive bias of 2D structure and any prior knowledge of the task that can be introduced during label assignment. When YOLOS models are fine-tuned on COCO, an optimal bipartite matching between predictions generated by [DET] tokens and the ground truth is established for each forward pass. This serves the same purpose as label assignment but is completely unaware of the input 2D structure, or even that it is 2D in nature.
What this means is that YOLOS does not need to re-interpret ViT’s output sequence to a 2D feature map for label assignment. YOLOS is designed with minimal inductive bias injection in mind. The only inductive biases it has have been inherited from the patch extraction at the network stem part of ViT and the resolution adjustment for position embeddings. Performance-oriented features of modern CNN architectures such as pyramidal feature hierarchy, region-wise pooling, and 2D spatial attention are not added.
This is all done to more accurately demonstrate the versatility and transferability of Transformer from image recognition to object detection in a pure sequence-to-sequence manner with minimal knowledge about the spatial structure of the input. As YOLOS doesn’t know anything about the spatial structure and geometry, it is feasible for it to perform any dimensional object detection as long as the input is flattened to a sequence in the same way. In addition to that, YOLOS can easily be adapted to numerous Transformers available in NLP and computer vision.
Results
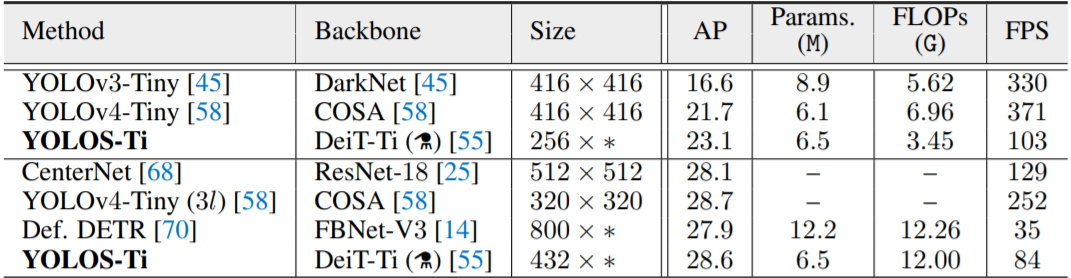
Comparisons with Tiny-sized CNN Detectors
To test its capabilities YOLOS was compared with some modern CNN-based object detectors. The smaller YOLOS variant YOLOS-Ti achieves impressive performance compared with existing highly-optimized CNN object detectors like YOLOv4 Tiny. It has strong AP and is competitive in FLOPs and FPS even though it was not intentionally designed to optimize these factors.
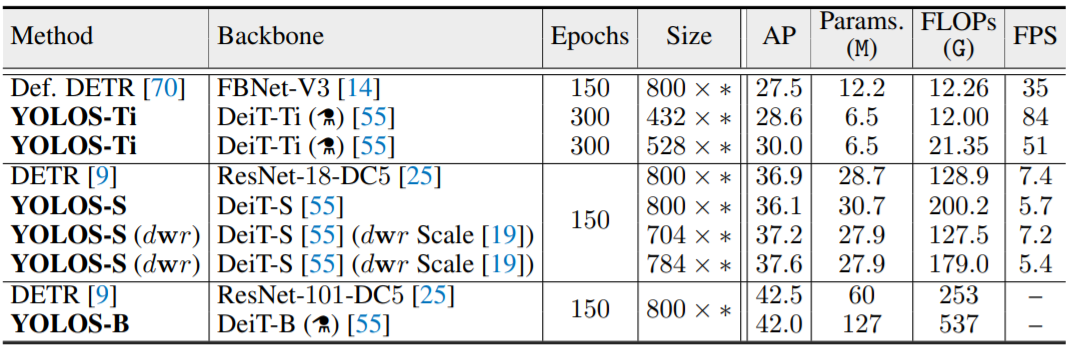
Comparisons with DETR
Although YOLOS-Ti performs better than the DETR counterpart, the larger YOLOS models with width scaling are less competitive. YOLOS-S with more computations is 0.8 AP lower compared with a similar-sized DETR model. What’s even worse is that YOLOS-B cannot beat DETR with basically twice the parameters and FLOPs. And while YOLOS-S with dwr(fast) scaling does manage to perform well, the performance gain cannot be clearly explained by the corresponding CNN scaling methodology used.
With these results, we have to keep in mind that YOLOS is not designed to be yet another high-performance object detector. It is merely a touchstone for the transferability of ViT from image recognition to object detection. To compare it with state-of-the-art models like YOLOR or YOLOX would be unfair. There are still many challenges that need to be resolved, but the performance on COCO is promising nonetheless. These initial findings effectively demonstrate the adaptability of Transformers to downstream tasks.

Do you want to be a computer vision professional but don’t know where to start? Enroll in our YOLOR course HERE today! It is a comprehensive course that covers not only object detection fundamentals and the state-of-the-art YOLOR model, but also the implementation of various use-cases & applications like the one shown above.

From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



