YOLOR vs YOLOX: Battle Of The Object Detection Prodigies
Apr 02, 2022
Object detection is one of the fundamental computer vision tasks. Although often confused with image recognition, object detection goes beyond mere classification. Simply put, object detection techniques mark the region of the image that contains the object with a bounding box. This ability to recognize the Region-Of-Interest (ROI) makes it the basis of many downstream tasks, for example, object tracking, image segmentation, landmark detection, and more. This means that everything from text detection to pedestrian tracking in self-driving cars uses object detection behind the scenes.
There are two broad paradigms of object detection techniques- single-stage detectors and two-stage detectors. Two-stage models like R-CNN, have an initial stage Region Proposal Network(RPN) that’s solely responsible for finding candidate regions in images along with an approximate bounding box for it. The second stage network uses the local features proposed by the RPN to determine the class and create a more refined bounding box. The separation of responsibility allows the second stage network to focus on learning the features isolated to the regions of interest proposed by the RPN, and thus leads to improved performance.
On the other hand, single-stage approaches such as YOLO have grid cells that map to different parts of the image, and every single grid cell is associated with several anchor boxes. Where each anchor box predicts an objectness probability(probability of the presence of an object), a conditional class probability, and bounding-box coordinates. Most grid-cells and anchors see “background” or no-object regions and a few see the ground-truth object. This hampers the learning ability of the CNN.
Historically, this was one of the main reasons for lower accuracy for single-stage detectors compared to two-stage approaches. However, over recent years new single-stage detection models have outperformed, if not matched, their two-stage counterparts. Let’s take a look at two of the latest YOLO variants introduced this year- YOLOR and YOLOX.
YOLOR

Looking at the same data features from different angles allows humans to answer a plethora of questions, something that’s not currently feasible for CNNs
Humans gain knowledge through deliberate learning (explicit knowledge), or subconsciously (implicit knowledge). The combination of the two types enables human beings to effectively process data, even unseen data. Furthermore, humans can analyze the same data points from different angles for different objectives. However, convolutional neural networks can only look at data from a single perspective. And the features outputted by CNNs are not adaptable to other objectives. The main cause for the issue is that CNNs only make use of the features from neurons, the explicit knowledge. All whilst not utilizing the abundant implicit knowledge.
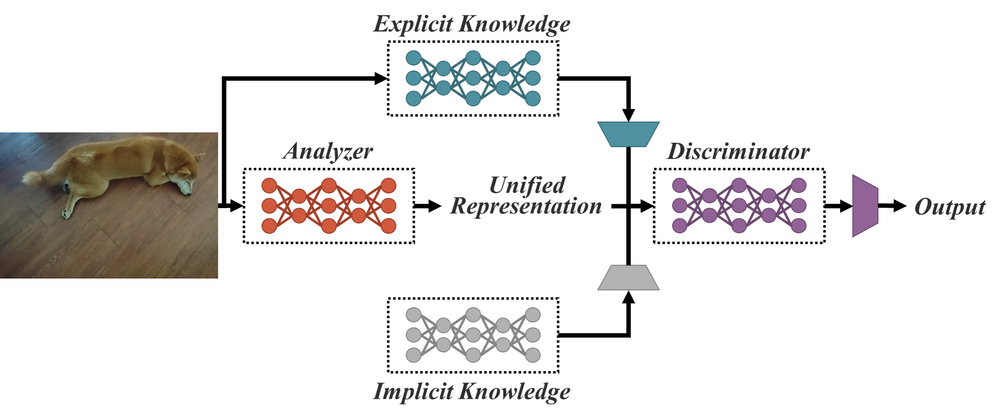
YOLOR’s unified network: combining explicit knowledge and implicit knowledge for serving multiple tasks
YOLOR (You Only Learn One Representation) is a unified network that integrates implicit knowledge and explicit knowledge. It pre-trains an implicit knowledge network with all of the tasks present in the COCO dataset to learn a general representation, i.e., implicit knowledge. To optimize for specific tasks, YOLOR trains another set of parameters that represent explicit knowledge. Both implicit and explicit knowledge are used for inference.
YOLOX
As mentioned earlier YOLO models take the image and draw a grid of different small squares. And then from these small squares, they regress off of the square to predict the offset they should predict the bounding box at. These grid cells alone give us tens of thousands of possible boxes, but YOLO models have anchor boxes on top of the grid. Anchor boxes have varying proportions that allow the model to detect objects of different sizes in different orientations. For example, if you have sharks and giraffes in a dataset, you would need skinny and tall anchor boxes for giraffes and wide and flat ones for sharks. Although the combination of these two enables the model to detect a wide range of objects, they also pose an issue in the form of increased computation cost and inference speed. Another limiting aspect of YOLO models is the coupling of bounding box regression and object detection tasks that causes a bit of a tradeoff.
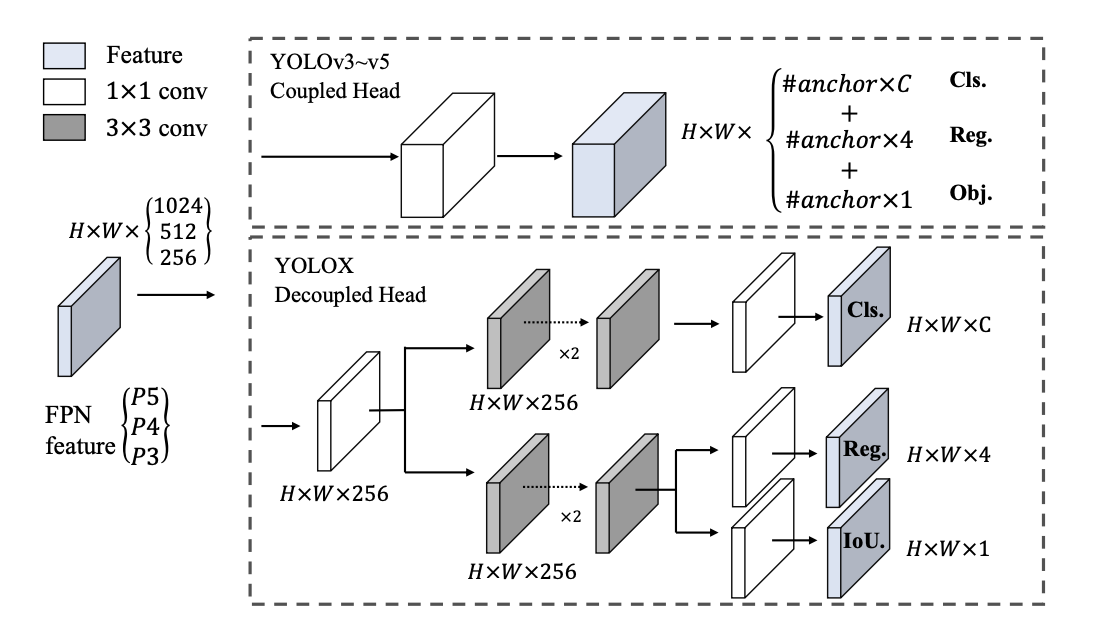
Difference between YOLOv3 head and the decoupled head used by YOLOX
YOLOX addresses both of these limitations, it drops box anchors altogether, this results in improved computation cost and inference speed. YOLOX also decouples the YOLO detection head into separate feature channels for box coordinate regression and object classification. This leads to improved convergence speed and model accuracy.
YOLOR vs YOLOX
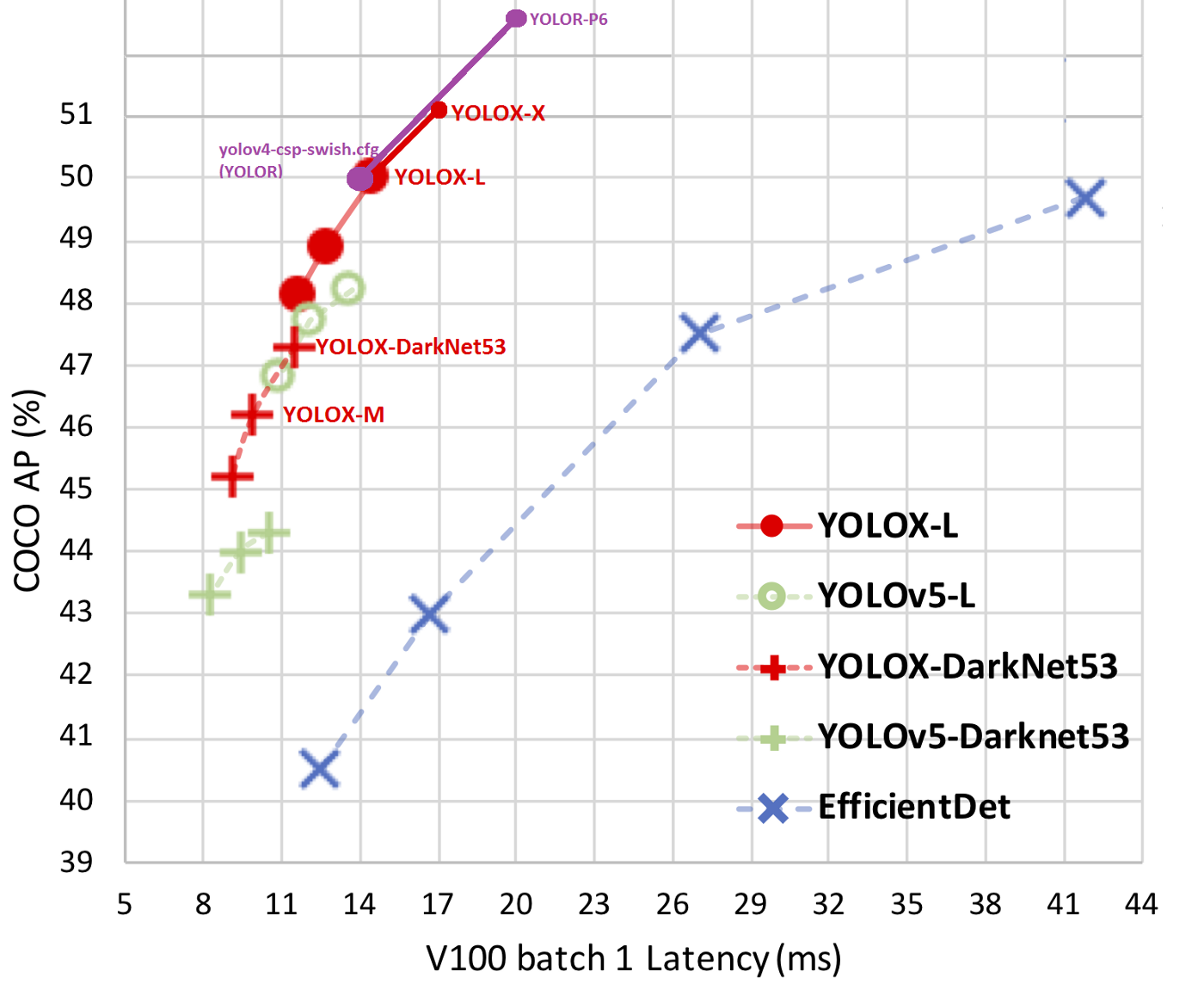
Accuracy vs latency plot for state-of-the-art single-stage detectors
Despite offering significant performance and speed boosts to existing state-of-the-art YOLO variants, YOLOX falls short of YOLOR in terms of sheer accuracy/mAP. However, YOLOX does show a lot of promise in terms of bringing better models to edge devices. Even with smaller model sizes, YOLOX-Tiny and YOLOX-Nano outperform their counterparts — YOLOv4-Tiny & NanoDet — significantly, offering a boost of 10.1% and 1.8% respectively.
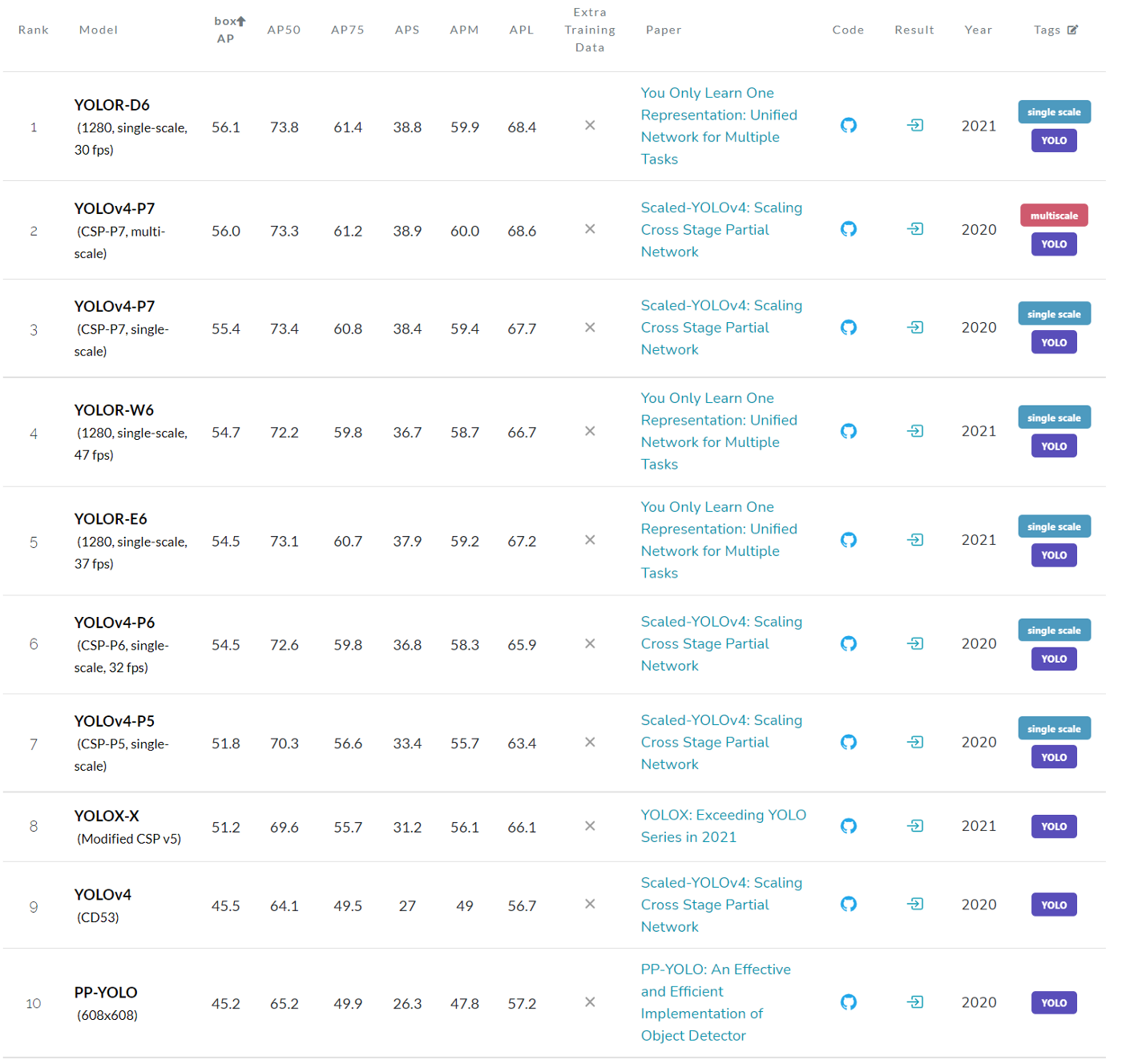
Leaderboard of all YOLO models for object detection on COCO test-dev dataset
On the object detection leaderboard for the COCO dataset, the only YOLO variant that comes close to YOLOR is Scaled-YOLOv4, and YOLOR is a whopping 88% faster than it! In addition to improved performance in object detection tasks, YOLOR’s unified network is very effective for multi-task learning. This means that the implicit knowledge learned by the model can be leveraged to perform a wide range of tasks beyond object detection such as key-point detection, image captioning, pose estimation, and many more. Furthermore, YOLOR can be extended to multi-modal learning like CLIP, enabling it to expand its implicit knowledge base even further and leverage other forms of data such as text and audio.
Let us know down in the comments, which YOLO model you would use for your project?
If you enjoyed this introduction to state-of-the-art object detection techniques and want to learn how to build real-world applications using YOLOR, you can enroll in our YOLOR course here.

From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



