ConvNext: The Return Of Convolution Networks
Feb 19, 2022
 Although back-propagation trained convolution neural networks (ConvNets) date all the way back to the 1980s, it was not until the 2010s that we saw their true potential. The decade was marked by tremendous growth and the impact of deep learning. One of the primary drivers for the ‘renaissance of neural networks’ was convolution networks. Over the decade, the field of computer vision went through a paradigm shift. We shifted from engineering features to designing architectures.
Although back-propagation trained convolution neural networks (ConvNets) date all the way back to the 1980s, it was not until the 2010s that we saw their true potential. The decade was marked by tremendous growth and the impact of deep learning. One of the primary drivers for the ‘renaissance of neural networks’ was convolution networks. Over the decade, the field of computer vision went through a paradigm shift. We shifted from engineering features to designing architectures.
And this dominance of ConvNets in computer vision was not a coincidence. ConvNets have several built-in inductive biases that make them well suited to a wide range of computer vision applications.
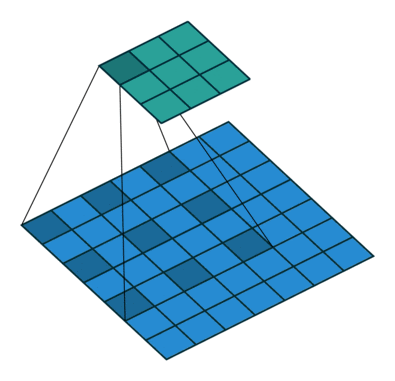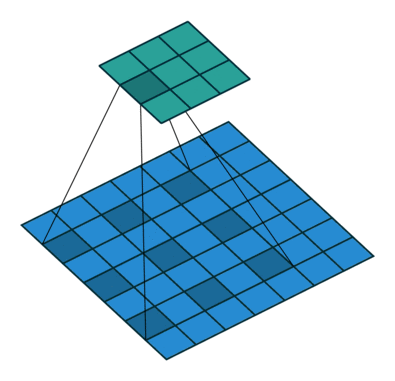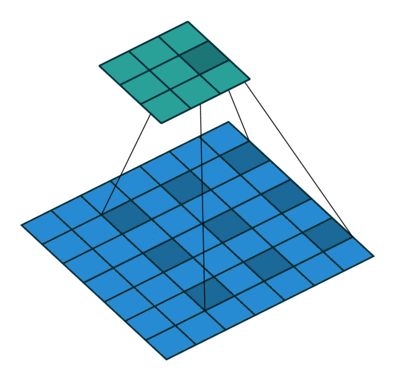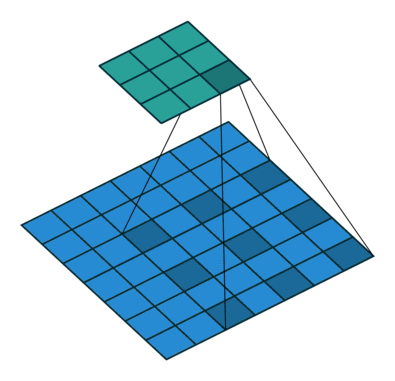
Sliding Window Approach Of Convolution Neural Networks
In many applications, a “sliding window” approach is essential to visual processing, particularly when working with high-resolution images.

Another important property of ConvNets is translation equivariance, which is a desirable property for tasks like objection detection. They are also inherently efficient due to the shared nature of computations in the sliding-windows approach.
Around the same time, the journey of neural networks for natural language processing (NLP) took a very different path. Recurrent neural networks were replaced by Transformers as the dominant backbone architecture. And despite the vast differences in the domains of language and vision, the two streams surprisingly converged in the year 2020 with the introduction of Vision Transformers (ViT).
 The “Patchify” Layer In The Vision Transformer Architecture [3]
The “Patchify” Layer In The Vision Transformer Architecture [3]
ViT completely changed our fundamental approach to network architecture design. Besides the addition of a “patchify” layer, which splits images into a sequence of flattened patches, ViT used no image-specific inductive bias and made minimal changes to the original NLP Transformers. One of the main reasons why Transformers like ViT became dominant is their scalability. With the help of larger models and dataset sizes, Transformers can outperform standard ResNets by a significant margin. The results on image classification tasks are inspiring, but computer vision goes way beyond simple classification.
Without the ConvNet inductive biases, a vanilla ViT model faces many challenges in being adopted as a generic vision backbone. ViT’s global attention design has a quadratic complexity with respect to the input size. This might be acceptable for ImageNet classification, but quickly becomes unmanageable with higher-resolution inputs.
 The Difference In Design Of Hierarchical Transformers [2]
The Difference In Design Of Hierarchical Transformers [2]
To overcome these shortcomings, hierarchical Transformers employ a hybrid approach. For instance, Swin Transformer reintroduced the “sliding window” approach was reintroduced to Transformers. This enabled Swin Transformer to become the first Transformer model that was adopted as a generic vision backbone and achieved state-of-the-art performance across a range of computer vision tasks beyond image classification.
But the thing is, this success of Swin Transformer just tells us that “the essence of convolution is not becoming irrelevant; rather, it remains much desired and has never faded.” On top of that, these attempts to bridge the gap made the transformer models more inefficient and complex. It is almost ironic that a ConvNet already satisfies many of the desired properties in a straightforward way. The only reason ConvNets are losing traction is that Transformers surpass them in many vision tasks due to their superior scaling behavior with multi-head self-attention being the key component.
Architecture & Approach
The design process of ConvNeXt was driven by one key question:
How do design decisions in Transformers impact ConvNets’ performance?
The authors start with a standard ResNet (e.g. ResNet50) and gradually “modernize” the architecture to the construction of a hierarchical vision Transformer (e.g. Swin-T).
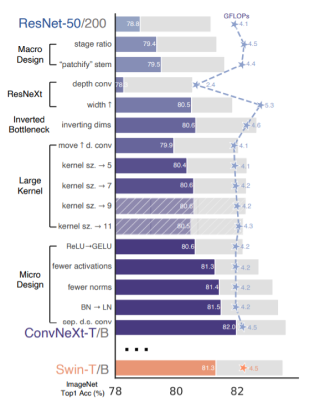
The Design Journey Of ConvNeXt
Training Methodology
Besides the network architecture, the training methodology also has a significant effect on the overall performance of the models. Vision Transformers introduced a new set of training techniques, like the AdamW optimizer, to the vision domain. These changes pertain mostly to the optimization strategy and associated hyper-parameter settings. Just by adopting these changes in the training methodology, the performance of the ResNet50 increased from 76.1% to 78.8%.
Macro Design
Swin Transformers follow ConvNets and use a multi-stage design, where each stage has a different feature map resolution. There are two design aspects to consider:
- Stage compute ratio
- The “stem cell” structure
The heavy “res4” stage in the original ResNet was meant to be compatible with downstream tasks like object detection. Although Swin-T followed the same principle, it has a slightly different stage compute ratio of 1:1:3:1. Following Swin, ConvNeXt changes the number of blocks in each stage from (3, 4, 6, 3) in ResNet-50 to (3, 3, 9, s3).
 Resnet-50 Stem Cell
Resnet-50 Stem Cell
The “stem” cell dictates how the input images will be processed at the network’s beginning. As there is a lot of redundancy in images, downsampling is a common standard for the stem cell in both Convolution Networks and Transformers. The standard ResNet has a 7×7 convolution layer with stride 2, followed by a max pool, which results in a 4×4 downsampling of the input images. Vision Transformers have a more aggressive “patchify” strategy, which corresponds to a large kernel size (like 14 or 16) and non-overlapping convolution. Swin Transformers use a similar layer, but with a smaller patch size of 4 to accommodate the architecture’s multi-stage design.
ConvNeXt replaces ResNet-style stem cell with a patchify layer implemented using a 4×4, stride 4 convolutional layer. These changes increase the accuracy from 78.8% to 79.4%.
ResNeXt-ify
ResNeXt has a better FLOPs/accuracy trade-off than a vanilla ResNet. The core component is grouped convolution, where the convolutional filters are separated into different groups. At a high level, ResNeXt’s guiding principle is to “use more groups, expand width”.
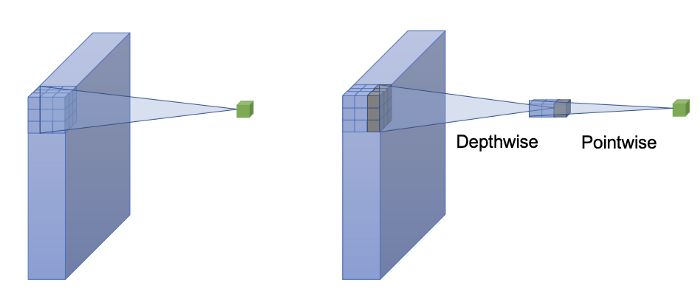
Standard Convolution, Depthwise Convolution & Pointwise Convolution
ConvNeXt uses depthwise convolution, a special case of grouped convolution where the number of groups equals the number of channels. Depthwise convolution is similar to the weighted sum operation in self-attention, which operates on a per-channel basis, i.e., only mixing information in the spatial dimension.
Depthwise convolution reduces the network FLOPs, and the accuracy. But following ResNeXt, ConvNeXt increases the network width from 64 to 96, the same number of channels as Swin-T. This brings the network performance to 80.5% with increased FLOPs (5.3G).
Inverted Bottleneck
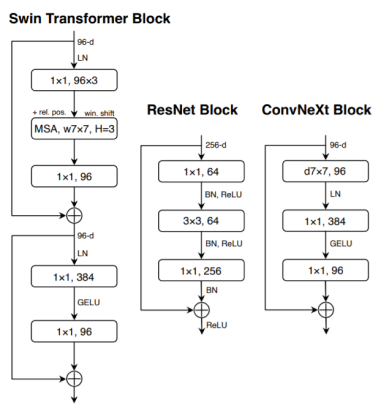
[1]
Another important aspect of the Transformer block is that it creates an inverted bottleneck, i.e., the hidden dimension of the MLP block is four times wider than the input dimension. Despite the increased FLOPs for the depthwise convolution layer, the inverted bottleneck design reduces the whole ConvNeXt network FLOPs to 4.6G. This is because of the significant FLOPs reduction in the downsampling residual blocks’ shortcut 1×1 convolution layer. Interestingly, this also slightly improves the performance from 80.5% to 80.6%.
Larger Kernel Size
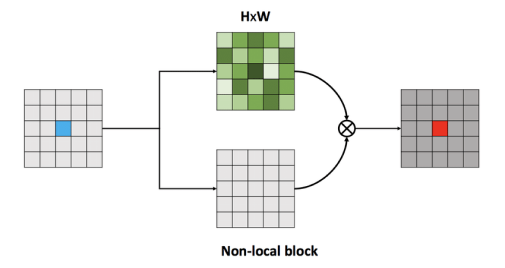
Non-Local Self-Attention Block
Beyond all that, the most differentiating aspect of vision Transformers is their non-local self-attention. While convolution networks are limited to the local features that fall within the size of the kernel, ViT’s non-local attention enables each layer to have a global receptive field, i.e., see the whole picture.
While large kernel sizes have been used in the past, the gold standard is small kernel-sized (3×3) Conv layers. The local window in Swin Transformers is at least 7×7, which is significantly larger than the ResNe(X)t kernel size of 3×3.
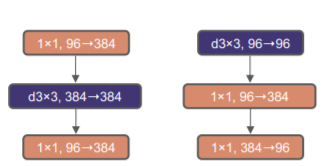
Moving Up The DepthWise Convolution Layer [1]
There’s a pre-requisite to explore larger kernels: moving up the position of the depthwise Conv layer. This is also seen in Transformers, the MSA block is placed prior to the MLP layers. This is a natural choice because of the inverted bottleneck. As a result of the rearranging, the more complex and efficient modules have fewer channels, and the dense 1x1 layer does most of the heavy lifting.
This change reduces the FLOPs to 4.1G, but it also causes a drop in performance to 79.9%. However, this drop is temporary as the adoption of a larger kernel-sized convolution is significant. ConvNeXt’s performance increases from 79.9% (3×3) to 80.6% (7×7), while the network’s FLOPs remain the same.
Micro Design
ConvNeXt also adopts some mirco scale architecture features from Transformers, i.e., layer level design aspects.
Activation Function

It replaces the ReLU activation function with its smoother variant Gaussian Error Linear Unit, GERU. Replicating the style of a Transfomer block, ConvNeXt drops all the GERU layers from the residual block except the one between two 1x1 Conv layers.
Normalization
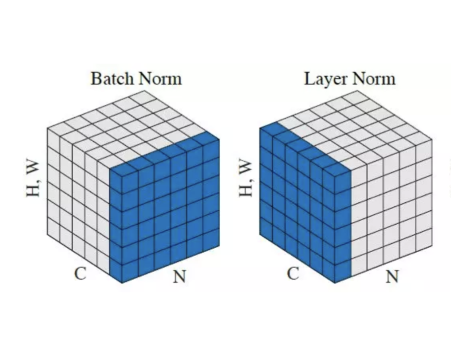
In addition to activation functions, Transformer blocks have fewer normalization functions as well. ConvNeXt eliminates two normalization layers and leaves only one before the 1x1 Conv layers. And, it replaces the BatchNorm is replaced by the simple Layer Normalization used by Transformers.
Lastly, ConvNeXt adds a separate downsampling layer between stages. It uses 2x2 Conv layers with a stride of 2 for downsampling.
Last Epoch
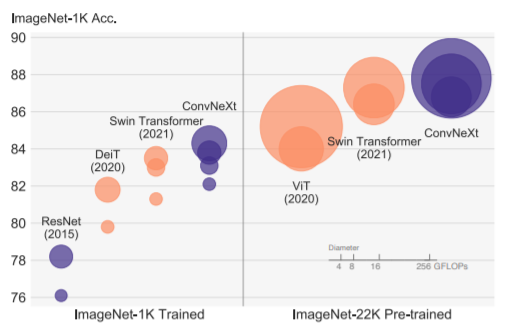
Plot of accuracies of different transformers and convolution architectures[1]
On ImageNet-1K, ConvNeXt competes admiringly with two strong ConvNet baselines — RegNet and EfficientNet in terms of the accuracy-computation trade-off, and, the inference throughputs. It also outperforms Swin Transformer without specialized modules such as shifted windows or relative position bias. Furthermore, ConvNeXts achieves better throughput (774.7 images/s) compared to Swin Transformers(757.9 images/s).
The general consensus is that transformers have fewer inductive biases and as a result, they perform better than ConvNet on larger scales. But this is refuted by the 87.8% accuracy of ConvNeXt-Xl on ImageNet-22K beating Swin Transformers.

COCO object detection and segmentation results using Mask-RCNN and Cascade Mask-RCNN[1]
Even on downstream tasks like object detection ConvNeXt based Mask R-CNN and Cascade Mask R-CNN achieves on-par or better performance than Swin Transformer.
And the best thing about all these improvements is that ConvNeXt maintains the efficiency of standard ConvNets, and the fully-convolutional nature for both training and testing. This makes it extremely simple to implement. The creators of ConvNeXt hope that “the new observations and discussions can challenge some common beliefs and encourage people to rethink the importance of convolutions in computer vision”.
If you learnt something in this article and want to get into Computer Vision, then check out our extensive computer vision courses HERE. Not only do we offer courses that cover state-of-the-art models like YOLOR, YOLOX, Siam Mask, but there are also guided projects such as pose/gesture detection and creating your very own smart glasses.

www.augmentedstartups.com/store
References
[1] A ConvNet for the 2020s
[2] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
[3] An Image is Worth 16x16 Words
[4] Deep Residual Learning for Image Recognition
From 80-Hour Weeks to 4-Hour Workflows
Get my Corporate Automation Starter Pack and discover how I automated my way from burnout to freedom. Includes the AI maturity audit + ready-to-deploy n8n workflows that save hours every day.
We hate SPAM. We will never sell your information, for any reason.



